
Architecture de Talend Data Preparation en mode cluster
Le diagramme suivant illustre l'architecture derrière Talend Data Preparation et Talend Dictionary Service lors d'une configuration en mode cluster.
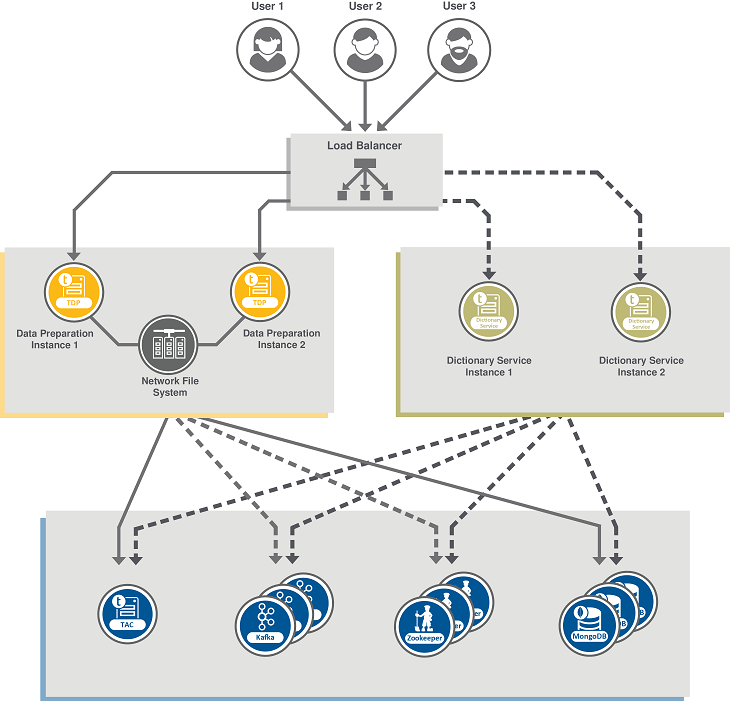
Cette architecture se compose de plusieurs blocs fonctionnels :
- Un répartiteur de charge (Load Balancer), distribuant la charge de travail des différent·e·s utilisateur·trices accédant en même temps aux instances de Talend Data Preparation et au(x) serveur(s) de Talend Dictionary Service.Note InformationsRemarque : Le même Load Balancer (répartiteur de charge) peut être utilisé pour Talend Data Preparation, Talend Data Stewardship et Talend Dictionary Service. De plus, le Load Balancer peut être physique ou logique.
- Les instances de Talend Data Preparation.
- Les instances de Talend Dictionary Service que vous pouvez installer de manière facultative si vous souhaitez ajouter, supprimer ou modifier les types sémantiques utilisés dans Talend Data Preparation.
- Un bloc contenant les différents composants nécessaires pour que Talend Data Preparation et Talend Dictionary Service fonctionnent, à savoir différentes instances de MongoDB pour le stockage, Kafka et ZooKeeper pour le messaging et une instance de Talend Administration Center pour gérer les autorisations.