
Rapprochement de plusieurs enregistrements
Bloc
Dans chaque bloc, les clés de bloc doivent avoir la même valeur. Ensuite, chacun des blocs est traité de manière indépendante.
L'utilisation de clés de bloc réduit le temps nécessaire aux algorithmes Simple VSR Matcher et T-Swoosh pour traiter les données. Par exemple, si 100 000 enregistrements sont partitionnés en 100 blocs de 1 000 enregistrements, le nombre de comparaisons est réduit d'un facteur 100. Ceci signifie que l'algorithme ira environ 100 fois plus vite.
Il est recommandé d'utiliser le tGenKey pour générer des clés de bloc et visualiser les statistiques concernant le nombre de blocs. Dans un Job, cliquez-droit sur le composant tGenKey et sélectionnez View Key Profile dans le menu contextuel afin de visualiser la distribution du nombre de blocs selon leur taille.
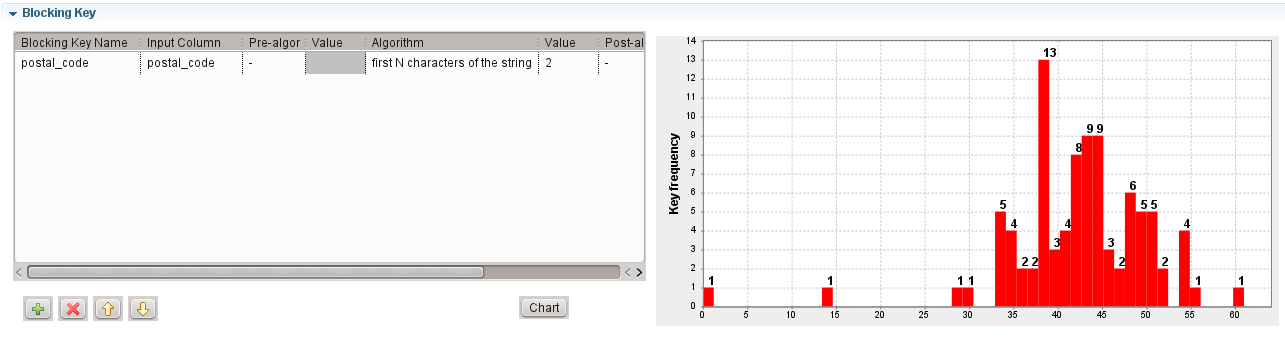
Dans cet exemple, la taille moyenne d'un bloc est d'environ 40.
Pour les 13 blocs contenant 38 lignes, il y aura 18 772 comparaisons au sein de ces 13 blocs (13 × 382). Si les enregistrements sont comparés sur quatre colonnes, il y aura 75 088 comparaisons de chaînes de caractères dans ces 13 blocs (18 772 × 4).
L'algorithme Simple VSR Matcher
Si un enregistrement ne correspond à aucun des enregistrements maître précédents, il est considéré comme étant un nouvel enregistrement maître et est ajouté à la table de contrôle. Cela signifie que le premier enregistrement du jeu de données est obligatoirement un enregistrement maître. L'ordre des enregistrements est donc important et peut influencer le processus de création des enregistrements maître.
Lorsqu'un enregistrement correspond à un enregistrement maître, l'algorithme Simple VSR Matcher ne cherche pas de correspondance avec d'autres enregistrements maître car les enregistrements maître de la table de contrôle ne sont pas similaires. Par conséquent, lorsqu'un enregistrement correspond à un enregistrement maître, ses chances de correspondre à un autre enregistrement maître sont faibles.
Cela signifie qu'un enregistrement ne peut exister que dans un seul groupe et n'être lié qu'à un seul enregistrement maître.
Par exemple, prenez le jeu d'enregistrements suivant en entrée :
| id | fullName |
|---|---|
| 1 | John Doe |
| 2 | Donna Lewis |
| 3 | John B. Doe |
| 4 | Louis Armstrong |
L'algorithme traite les enregistrements en entrée comme suit :
- L'algorithme prend l'enregistrement 1 et le compare à un jeu de données vide. Puisque l'enregistrement 1 ne correspond à aucun enregistrement, il est ajouté à la table de contrôle.
- L'algorithme prend l'enregistrement 2 et le compare à l'enregistrement 1. Puisqu'il n'y a pas de correspondance, l'enregistrement 2 est ajouté à la table de contrôle.
- L'algorithme prend l'enregistrement 3, puis le compare à l'enregistrement 1 et à l'enregistrement 2. L'enregistrement 3 correspond à l'enregistrement 1. Par conséquent, l'enregistrement 3 est ajouté au groupe de l'enregistrement 1.
- L'algorithme prend l'enregistrement 4, puis le compare à l'enregistrement 1 et à l'enregistrement 2 mais pas avec l'enregistrement 3, qui n'est pas un enregistrement maître. Puisqu'il n'y a pas de correspondance, l’enregistrement 4 est ajouté à la table de contrôle.
La sortie ressemblera à la table suivante :
| id | fullName | Grp_ID | Grp_Size | Master | Score | GRP_QUALITY |
|---|---|---|---|---|---|---|
| 1 | John Doe | 0 | 2 | true | 1.0 | 0.72 |
| 3 | John B. Doe | 0 | 0 | false | 0.72 | 0 |
| 2 | Donna Lewis | 1 | 1 | true | 1.0 | 1.0 |
| 4 | Louis Armstrong | 2 | 1 | true | 1.0 | 1.0 |
L'algorithme T-Swoosh
L'algorithme T-Swoosh est basé sur la même idée que l'algorithme Simple VSR Matcher mais il crée un enregistrement maître au lieu de considérer les enregistrements existants comme des enregistrements maître.
L'ordre des enregistrements d'entrée n'impacte pas le processus de rapprochement.
Pour créer des enregistrements maître, vous pouvez concevoir des règles de consolidation afin de décider de l'attribut qui sera consolidé.
Il existe deux types de règles de consolidation :
- Les règles liées aux clés de rapprochement : chaque attribut utilisé en tant que clé de rapprochement peut avoir une règle de consolidation spécifique.
- Les règles par défaut : elles sont appliquées aux attributs ayant le même type (Boolean, String, Date, Number).
Si une colonne est une clé de rapprochement, la règle liée aux clés de rapprochement, spécifique à cette colonne, est appliquée.
Si la colonne n'est pas une clé de rapprochement, la règle de consolidation par défaut pour ce type de données est appliquée. Si la règle de consolidation par défaut n'est pas définie pour ce type de données, la fonction de consolidation Most common est utilisée.
Chaque fois que deux enregistrements sont fusionnés pour créer un enregistrement maître, ce nouvel enregistrement maître est ajouté à la file d'attente des enregistrements à examiner. Les deux enregistrements fusionnés sont supprimés de la table de contrôle.
Par exemple, prenez le jeu d'enregistrements suivant en entrée :
| id | fullName |
|---|---|
| 1 | John Doe |
| 2 | Donna Lewis |
| 3 | John B. Doe |
| 4 | Johnnie B. Doe |
La règle de consolidation utilise la fonction Concatenate avec "," comme paramètre pour séparer les valeurs.
Au début du processus, la file d'attente contient tous les enregistrements en entrée et la table de contrôle est vide. Afin de traiter les enregistrements en entrée, l'algorithme itère jusqu'à ce que la file d'attente soit vide :
- L'algorithme prend l'enregistrement 1 et le compare à un jeu de données vide. Puisque l'enregistrement 1 ne correspond à aucun enregistrement, il est ajouté aux enregistrements maître. La file d'attente contient maintenant l'enregistrement 2, l'enregistrement 3 et l'enregistrement 4. La table de contrôle contient l'enregistrement 1.
- L'algorithme prend l'enregistrement 2 et le compare à l'enregistrement 1. Puisque l'enregistrement 2 ne correspond à aucun enregistrement, il est ajouté aux enregistrements maître. La file d'attente contient maintenant l'enregistrement 3 et l'enregistrement 4. La table de contrôle contient l'enregistrement 1 et l'enregistrement 2.
- L'algorithme prend l'enregistrement 3 et le compare à l'enregistrement 1. L'enregistrement 3 correspond à l'enregistrement 1. Par conséquent, l'enregistrement 1 et l'enregistrement 3 sont fusionnés pour créer un enregistrement maître, appelé enregistrement 1,3. La file d'attente contient maintenant l'enregistrement 4 et l'enregistrement 1,3. La table de contrôle contient l'enregistrement 2.
- L'algorithme prend l'enregistrement 4 et le compare à l'enregistrement 2. Puisqu'il n'y a pas de correspondance, l'enregistrement 4 est ajouté aux enregistrements maître. La file d'attente contient maintenant l'enregistrement 1,3. La table de contrôle contient l'enregistrement 2 et l'enregistrement 4.
- L'algorithme prend l'enregistrement 1,3, puis le compare à l'enregistrement 2 et à l'enregistrement 4. L'enregistrement 1,3 correspond à l'enregistrement 4. Par conséquent, l'enregistrement 1,3 et l'enregistrement 4 sont fusionnés pour créer un enregistrement maître appelé enregistrement 1,3,4. L'enregistrement 4 est supprimé de la table de contrôle. Puisque l'enregistrement 1,3 était le résultat d'une fusion, il est supprimé de cette table. La file d'attente contient maintenant l'enregistrement 1,3,4. La table de contrôle contient l'enregistrement 2.
- L'algorithme prend l'enregistrement 1,3,4 et le compare à l'enregistrement 2. Puisqu'il n'y a pas de correspondance, l'enregistrement 1,3,4 est ajouté aux enregistrements maître. La file d'attente est désormais vide. La table de contrôle contient l'enregistrement 1,3,4 et l'enregistrement 2.
La sortie ressemblera à la table suivante :
| id | fullName | GRP_ID | GRP_SIZE | MASTER | SCORE | GRP_QUALITY |
|---|---|---|---|---|---|---|
| 1,3,4 | John Doe, John B. Doe, Johnnie B. Doe | 0 | 3 | true | 1.0 | 0.449 |
| 1 | John Doe | 0 | 0 | false | 0.72 | 0 |
| 3 | John B. Doe | 0 | 0 | false | 0.72 | 0 |
| 4 | Johnnie B. Doe | 0 | 0 | false | 0.78 | 0 |
| 2 | Donna Lewis | 1 | 1 | true | 1.0 | 1.0 |
Comme vous pouvez le constater, la valeur de la colonne GRP_QUALITY peut être inférieure à la valeur du paramètre Match Threshold. Cela est possible car un groupe est créé à partir de paires d'enregistrements avec un score de rapprochement supérieur ou égal à la valeur de Match Threshold, mais les enregistrements ne sont pas tous comparés les uns aux autres, tandis que GRP_QUALITY prend en compte toutes les paires d'enregsitrements dans le groupe.
Les différences entre les algorithmes Simple VSR Matcher et T-Swoosh
Il s'agit de l'une des principales différences entre les algorithmes Simple VSR Matcher et T-Swoosh.
- Lorsque vous utilisez l'algorithme Simple VSR matcher, l'enregistrement appartenant à la file d'attente est uniquement comparé à la valeur de l'enregistrement maître. Il n'y a aucune comparaison entre l'enregistrement appartenant à la file d'attente et la valeur des enregistrements utilisés pour créer cet enregistrement maître. Vous devez donc classer les enregistrements dans les données d'entrée pour que les enregistrements les plus fiables apparaissent en premiers.
- Lorsque vous utilisez l'algorithme T-Swoosh, l'enregistrement appartenant à la file d'attente est comparé à la valeur de l'enregistrement maître et à la valeur de chacun des enregistrements utilisés pour créer cet enregistrement maître, jusqu'à ce qu'il y ait une correspondance.
Pour un exemple de création d'enregistrements consolidés à l'aide de l'algorithme T-Swoosh, consultez L'algorithme T-Swoosh.
Dans cet exemple, l'enregistrement "John Doe, John B. Doe" est comparé à "John B. Doe" lors de l'itération 5. Il y a une correspondance si au moins une des trois chaînes de caractères, "John Doe, John B. Doe", "John Doe" et "John B. Doe", correspond à la chaîne "Johnnie B. Doe".