
複数レコードのマッチング
ブロッキング
どのブロックでも、ブロッキングキーの値は同じである必要があります。続いて、各ブロックが個別に処理されます。
ブロッキングキーを使用すると、シンプルVSRマッチャーとT-Swooshアルゴリズムがデータ処理に必要とする時間が短縮されます。たとえば、100,000レコードが1,000レコード×100ブロックに分割されると、比較の件数が100分の1に減少します。このため、アルゴリズムの実行速度は約100倍になります。
tGenKeyコンポーネントを使用してブロッキングキーを生成し、ブロック数に関する統計を視覚化することをお勧めします。ジョブ内でtGenKeyコンポーネントを右クリックし、コンテキストメニューで[View Key Profile] (キープロファイルの表示)を選択して、ブロック数のディストリビューションをそのサイズに従って視覚化します。
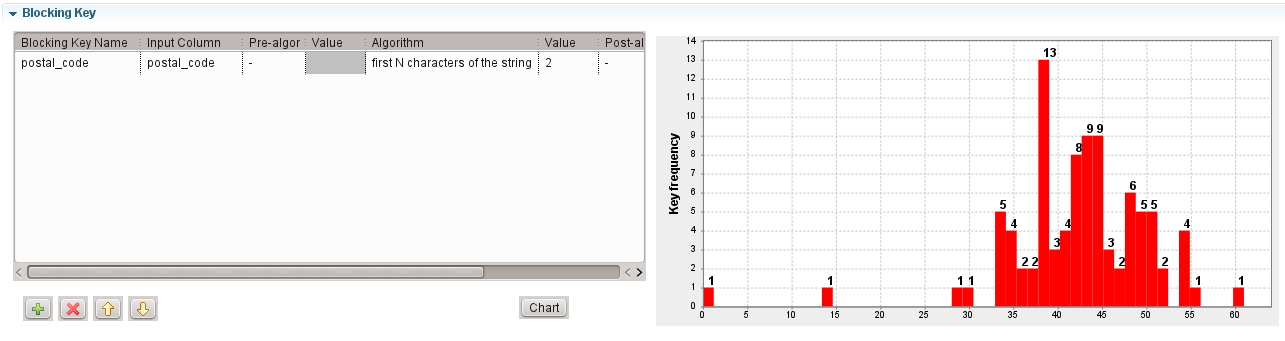
この例では、ブロックサイズの平均は約40です。
38行のブロックが13ある場合、13のブロックには18,772の比較があります(13 × 382)。レコードを4カラムで比較すると、これら13のブロックには75,088文字列の比較があります(18,772 × 4)。
シンプルVSRマッチャーアルゴリズム
前のマスターレコードのどれにもマッチングしないレコードがある場合は、新しいマスターレコードと見なされ、ルックアップテーブルに追加されます。すなわち、データセットの最初のレコードは必然的にマスターレコードとなります。そのため、レコードの順序が重要であり、マスターレコードの作成プロセスに影響を及ぼす可能性があります。
あるレコードがマスターレコードにマッチングすると、シンプルVSRマッチャーアルゴリズムはそれ以降他のマスターレコードとのマッチングを試みません。ルックアップテーブル内のマスターレコードがどれも類似していないためです。したがって、あるレコードがマスターレコードとマッチングすると、別のマスターレコードにマッチングする可能性は低いです。
すなわち、レコードは1つのレコードグループ内にのみ存在でき、1つのマスターレコードにのみリンクされることが可能です。
たとえば、以下のレコードのセットを入力として取り込みます。
| id | fullName |
|---|---|
| 1 | John Doe |
| 2 | Donna Lewis |
| 3 | John B. Doe |
| 4 | Louis Armstrong |
アルゴリズムは入力レコードを以下のように処理します。
- アルゴリズムはレコード1を取り、空のレコードセットと比較します。レコード1はどのレコードともマッチングしないため、ルックアップテーブルに追加されます。
- アルゴリズムはレコード2を取り、レコード1と比較します。マッチではないため、レコード2はルックアップテーブルに追加されます。
- アルゴリズムはレコード3を取り、レコード1、レコード2と比較します。レコード3はレコード1とマッチングするため、レコード3がレコード1のグループに追加されます。
- アルゴリズムはレコード4を取り、レコード1およびレコード2と比較しますが、マスターレコードではないレコード3とは比較しません。マッチングではないため、レコード4がルックアップテーブルに追加されます。
出力は次のようになります。
| id | fullName | Grp_ID | Grp_Size | マスター | スコア | GRP_QUALITY |
|---|---|---|---|---|---|---|
| 1 | John Doe | 0 | 2 | true | 1.0 | 0.72 |
| 3 | John B. Doe | 0 | 0 | false | 0.72 | 0 |
| 2 | Donna Lewis | 1 | 1 | true | 1.0 | 1.0 |
| 4 | Louis Armstrong | 2 | 1 | true | 1.0 | 1.0 |
T-Swooshアルゴリズム
T-SwooshアルゴリズムはシンプルVSRマッチャーアルゴリズムと同じ考え方に基づいていますが、既存のレコードをマスターレコードと見なすのではなく、マスターレコードを作成します。
入力レコードの順序はマッチングプロセスには影響しません。
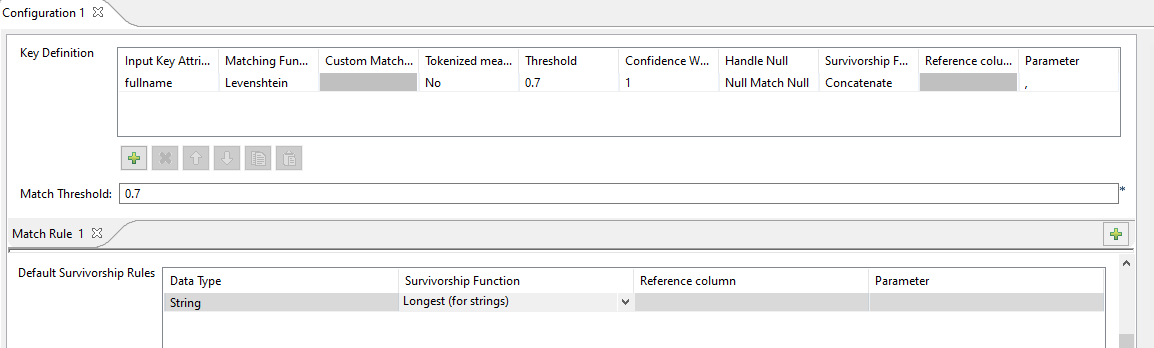
マスターレコードを作成するには、どの属性を残すかを決めるためにサバイバーシップルールをデザインします。
サバイバーシップルールには次の2つのタイプがあります。
- マッチングキーに関連するルール: マッチングするキーとして使用される各属性に特定のサバイバーシップルールを設定できます。
- デフォルトのルール: データ型が等しいすべての属性に適用されます(ブール値、文字列、日付、数値)。
カラムがマッチングキーである場合は、このカラムに固有のマッチングキーに関連するルールが適用されます。
カラムがマッチングキーでない場合は、このデータ型のデフォルトサバイバーシップルールが適用されます。データ型のデフォルトサバイバーシップルールが定義されていない場合は、[Most common] (最も一般的)なサバイバーシップ機能が使用されます。
2つのレコードをマージして新しいマスターレコードを作成した時は毎回、この新しいマスターレコードが、検査するレコードのキューに追加されます。マージされた2つのレコードは、ルックアップテーブルから削除されます。
たとえば、以下のレコードのセットを入力として取り込みます。
| id | fullName |
|---|---|
| 1 | John Doe |
| 2 | Donna Lewis |
| 3 | John B. Doe |
| 4 | Johnnie B. Doe |
サバイバーシップルールでは、[Concatenate] (連結)ファンクションと","が、値を区切るパラメーターとして使用されます。
プロセスの最初の段階では、キューにはすべての入力レコードが含まれており、ルックアップは空です。入力レコードを処理するために、アルゴリズムはキューが空になるまで反復されます。
- アルゴリズムはレコード1を取り、空のレコードセットと比較します。レコード1はどのレコードともマッチングしないため、マスターレコードのセットに追加されます。これで、キューにはレコード2、レコード3、レコード4が含まれています。ルックアップにはレコード1が含まれています。
- アルゴリズムはレコード2を取り、レコード1と比較します。レコード2はどのレコードともマッチングしないため、マスターレコードのセットに追加されます。これで、キューにはレコード3、レコード4が含まれています。ルックアップにはレコード1とレコード2が含まれています。
- アルゴリズムはレコード3を取り、レコード1と比較します。レコード3はレコード1とマッチングします。そのため、レコード1とレコード3がマージされて、レコード1,3という新しいマスターレコードが作成されます。これで、キューにはレコード4とレコード1,3が含まれています。ルックアップにはレコード2が含まれています。
- アルゴリズムはレコード4を取り、レコード2と比較します。マッチではないため、レコード4はマスターレコードのセットに追加されます。これで、キューにはレコード1,3が含まれています。ルックアップテーブルにはレコード2とレコード4が含まれています。
- アルゴリズムはレコード1,3を取り、レコード2、レコード4と比較します。レコード1,3はレコード4とマッチングします。そのため、レコード1,3とレコード4がマージされて、レコード1,3,4という新しいマスターレコードが作成されます。レコード4はルックアップテーブルから削除されます。レコード1,3は前のマージの結果であるため、テーブルから削除されます。これで、キューにはレコード1,3,4が含まれています。ルックアップにはレコード2が含まれています。
- アルゴリズムはレコード1,3,4を取り、レコード2と比較します。マッチではないため、レコード1,3,4はマスターレコードのセットに追加されます。現在、キューは空です。ルックアップにはレコード1,3,4とレコード2が含まれています。
出力は次のようになります。
| id | fullName | GRP_ID | GRP_SIZE | MASTER | SCORE | GRP_QUALITY |
|---|---|---|---|---|---|---|
| 1,3,4 | John Doe, John B. Doe, Johnnie B. Doe | 0 | 3 | true | 1.0 | 0.449 |
| 1 | John Doe | 0 | 0 | false | 0.72 | 0 |
| 3 | John B. Doe | 0 | 0 | false | 0.72 | 0 |
| 4 | Johnnie B. Doe | 0 | 0 | false | 0.78 | 0 |
| 2 | Donna Lewis | 1 | 1 | true | 1.0 | 1.0 |
このサンプルでわかるように、GRP_QUALITYカラムは[Match Threshold] (マッチングしきい値)パラメーターよりも小さくできます。これは、[Match Threshold] (マッチングしきい値)以上のマッチングスコアを持つレコードペアからグループが作成されますが、すべてのレコードが互いに比較されるわけではないためです。他方、GRP_QUALITYはグループ内のすべてのレコードペアを考慮に入れます。
シンプルVSRマッチャーとT-Swooshアルゴリズムの違い
これは、シンプルVSRマッチャーとT-Swooshアルゴリズムの主な違いの1つです。
- シンプルVSRマッチャーアルゴリズムを使用する場合、キューからのレコードはマスターレコードの値とだけ比較されます。キューからのレコードと、このマスターレコードをビルドするために使用される各レコードの値との間で、比較は行われません。次に、最も信頼性が高いレコードが入力データの最初に表示されるように入力レコードをソートします。
- T-Swooshアルゴリズムを使用する場合、キューからのレコードがマスターレコードの値および、このマスターレコードをビルドするために使用された各レコードの値と比較されます。この比較は、レコードがマッチングと見なされるまで続きます。
T-Swooshアルゴリズムを使用してマスターレコードを存続させるサンプルは、T-Swooshアルゴリズムをご覧ください。
この例では、"John Doe, John B. Doe"というレコードが、反復5の"John B. Doe"というレコードと比較されます。"John Doe, John B. Doe"、"John Doe"、"John B. Doe"という3つの文字列の少なくとも1つが文字列 "Johnnie B. Doe"とマッチングすれば、マッチングがあることになります。