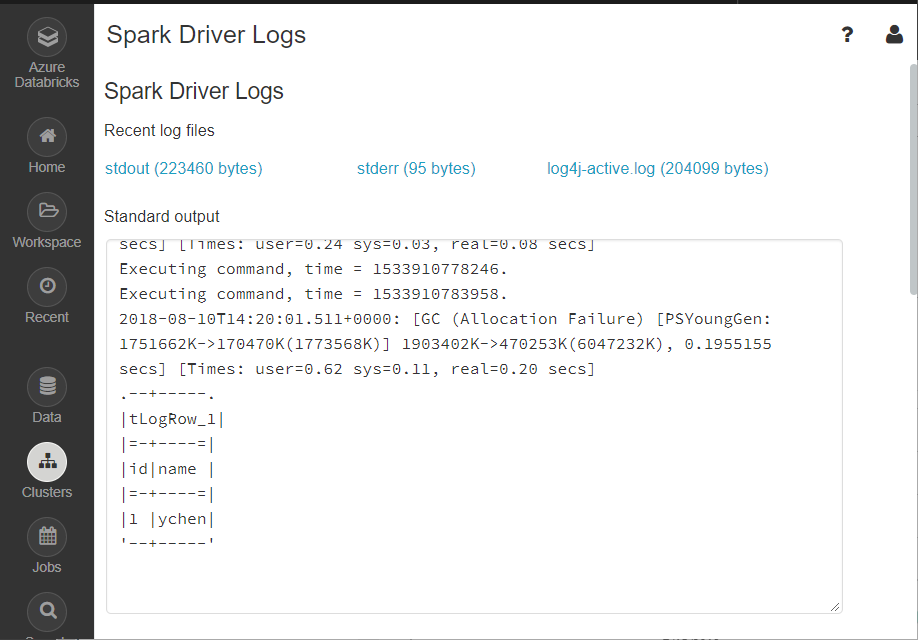
Lire les données d'exemple depuis Azure Data Lake Storage
Procédure
-
Double-cliquez sur le tFileInputParquet pour ouvrir sa vue Component.
Exemple
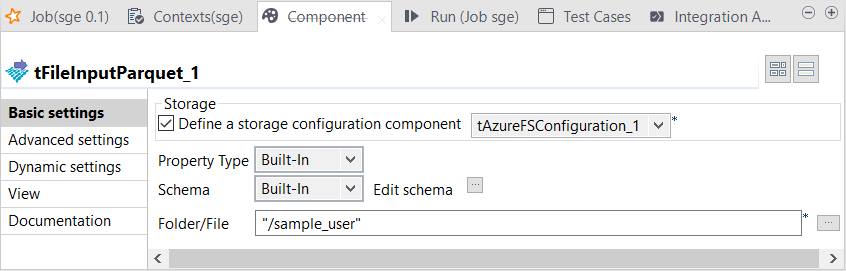
-
Cliquez sur le bouton [+] afin d'ajouter les colonnes du schéma, pour la sortie, comme dans l'image ci-dessous.
Exemple
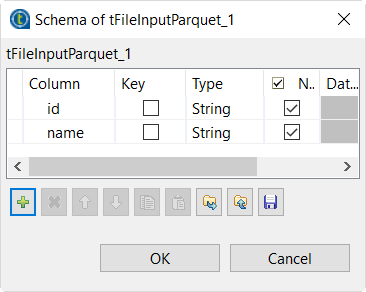
Résultats