
ランダムフォレストを使って分類モデルを作成する
このシナリオでは、ランダムフォレストを使った分類モデルの作成方法を説明します。
データフローを配列する
手順
-
[Row] (行) > [Main] (メイン)リンクを使い、tHDFSConfiguration以外のコンポーネントを接続させます。

Sparkが使用するファイルシステムに接続を設定
手順は、Getting Started Guideをご覧ください。
トレーニングセットを読み取る
手順
-
tFileInputDelimitedをダブルクリックして、[Component] (コンポーネント)ビューを開きます。

-
[+]ボタンを5回クリックして5つの行を追加し、[Column] (カラム)カラムで名前をそれぞれlabel、sms_contents、num_currency、num_numeric、num_exclamationに変更します。
 labelカラムとsms_contentsカラムは、sms_contentsカラム内のSMSテキストメッセージで構成された生データを保持し、メッセージがスパムかどうかをlabelカラムでラベル表示します。他のカラムは、このシナリオで前に説明したように、生データセットに追加された機能を保持するために使われます。これらの3つの機能は、各SMSメッセージにある通貨記号の数、数値の数、感嘆符の数です。
labelカラムとsms_contentsカラムは、sms_contentsカラム内のSMSテキストメッセージで構成された生データを保持し、メッセージがスパムかどうかをlabelカラムでラベル表示します。他のカラムは、このシナリオで前に説明したように、生データセットに追加された機能を保持するために使われます。これらの3つの機能は、各SMSメッセージにある通貨記号の数、数値の数、感嘆符の数です。
tModelEncoderを使ってSMSテキストメッセージを特徴ベクターに変換する
このステップには、4つのサブステップ(メッセージを単語に変換、各メッセージ内の単語の重みを計算、各メッセージ内の無関係な単語の重みを軽減、特徴ベクターを結合)を必要とします。
手順
-
メッセージを単語に変換する方法:
-
[Tokenize] (トークン化)とラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。このコンポーネントは、SMSメッセージを単語にトークン化します。

-
出力側で[+]ボタンをクリックして1行を追加し、[Column] (カラム)カラムで名前をsms_tokenizer_wordsに変更します。このカラムは、トークン化されたメッセージを保持するために使われます。
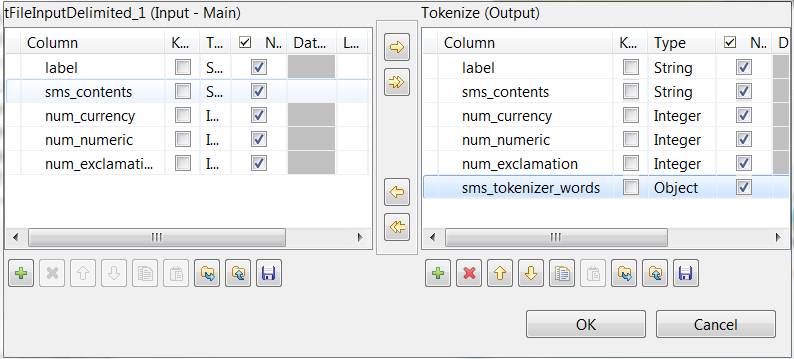
-
[Tokenize] (トークン化)とラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。このコンポーネントは、SMSメッセージを単語にトークン化します。
-
各メッセージ内の単語の重みを計算する方法:
-
tfとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。

-
Tokenizeというラベルが付けられたtModelEncoderに前述の操作を繰り返して、Vector型のsms_tf_vectカラムを出力スキーマに追加し、上の画像に示すように変換を定義します。

この変換では、tModelEncoderはHashingTFを使って、トークン化済みのSMSメッセージを固定長(このシナリオでは15)の特徴ベクターに変換し、各SMSメッセージの単語の重要性を反映します。
-
tfとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。
-
各メッセージ内の無関係な単語の重みを軽減する方法:
-
tf_idfとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。
この処理で、tModelEncoderは出現頻度が非常に高いものの、出現しているメッセージが多すぎる単語の重みを軽くします。この種の単語は、theのようにテキスト分析に有意な情報をもたらさない場合が多いためです。

-
Tokenizeというラベルが付けられたtModelEncoderに前述の操作を繰り返して、Vector型のsms_tf_idf_vectカラムを出力スキーマに追加し、上の画像に示すように変換を定義します。

この変換では、tModelEncoderは[Inverse Document Frequency] (文献出現頻度の逆数)を使って、5つ以上のメッセージに出現する単語の重みを軽くします。
-
tf_idfとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。
-
特徴ベクターを結合させる方法:
-
features_assemblerとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。

-
Tokenizerとラベル表示されたtModelEncoderに前述の操作を繰り返して、Vector型のfeatures_vectカラムを出力スキーマに追加し、上の画像に示すように変換を定義します。
[Parameters] (パラメーター)カラムに入力するパラメーターはinputCols=sms_tf_idf_vect,num_currency,num_numeric,num_exclamationです。
 この変換では、tModelEncoderはすべての機能Vectorを1つの機能カラムに結合します。
この変換では、tModelEncoderはすべての機能Vectorを1つの機能カラムに結合します。
-
features_assemblerとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。
ランダムフォレストを使ってモデルをトレーニングする
手順
-
tRandomForestModelをダブルクリックして[Component] (コンポーネント)ビューを開きます。

Sparkモードの選択
手順は、Getting Started Guideをご覧ください。
ジョブを実行して分類モデルを作成する
手順
F6を押してこのジョブを実行します。