
Creating a classification model using Random Forest
This scenario explains how to create a classification model using Random
Forest.
Arranging the data flow
Procedure
-
Except tHDFSConfiguration,
connect the other components using the Row >
Main link.
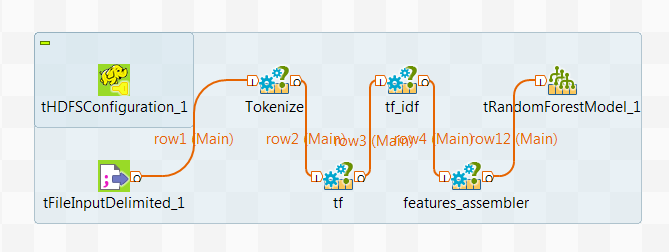
Configuring the connection to the file system to be used by Spark
See the procedure in the Getting Started Guide.
Reading the training set
Procedure
-
Double-click tFileInputDelimited to open its Component view.
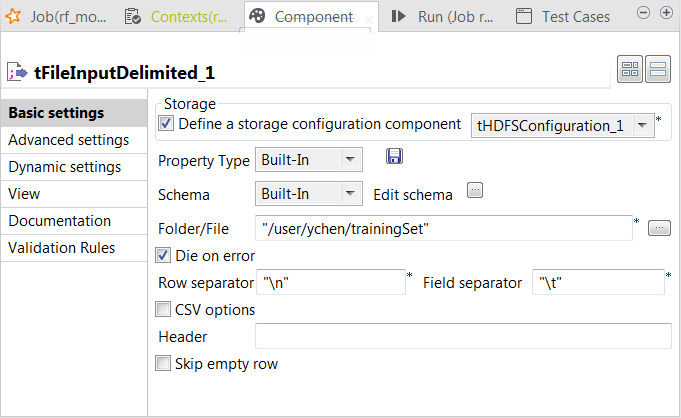
-
Click the [+] button five
times to add five rows and in the Column
column, rename them to label, sms_contents, num_currency, num_numeric and num_exclamation,
respectively.
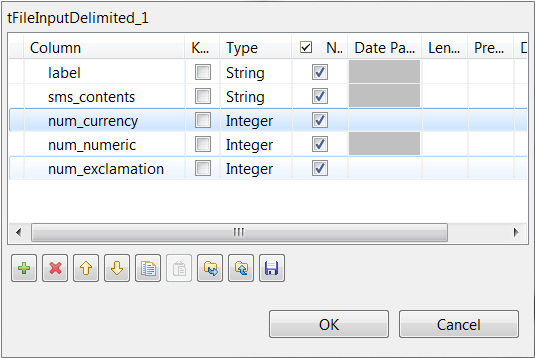 The label and the sms_contents columns carries the raw data which is composed of the SMS text messages in the sms_contents column and the labels indicating whether a message is spam in the label column.The other columns are used to carry the features added to the raw datasets as explained previously in this scenario. These three features are the number of currency symbols, the number of numeric values and the number of exclamation marks found in each SMS message.
The label and the sms_contents columns carries the raw data which is composed of the SMS text messages in the sms_contents column and the labels indicating whether a message is spam in the label column.The other columns are used to carry the features added to the raw datasets as explained previously in this scenario. These three features are the number of currency symbols, the number of numeric values and the number of exclamation marks found in each SMS message.
Transforming SMS text messages to feature vectors using tModelEncoder
This step requires four substeps: transforming the message to words, calculating
the weight of a word in each message, downplaying the weight of the irrelevant words in
each message, and combining feature vectors.
Procedure
-
To transform messages to words:
-
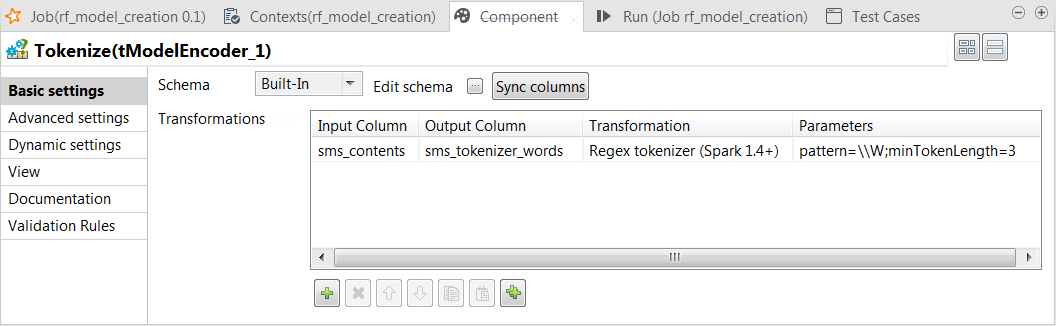
Double-click the tModelEncoder
component labeled Tokenize to open its Component view. This component tokenize the SMS
messages into words.
-
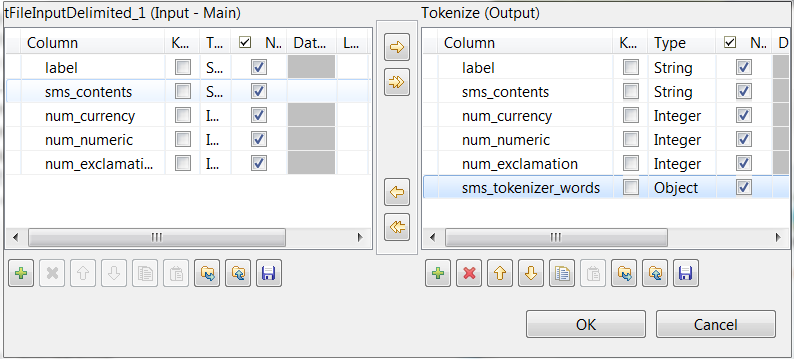
On the output side, click the [+]
button to add one row and in the Column
column, rename it to sms_tokenizer_words. This column is
used to carry the tokenized messages.
-
Double-click the tModelEncoder
component labeled Tokenize to open its Component view. This component tokenize the SMS
messages into words.
-
To calculate the weight of a word in each message:
-
Double-click the tModelEncoder
component labeled tf to open its Component view.
-
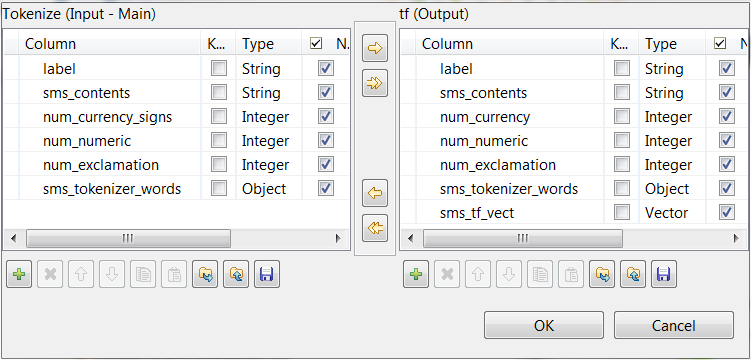
Repeat the operations described previously over the tModelEncoder labeled
Tokenize to add the
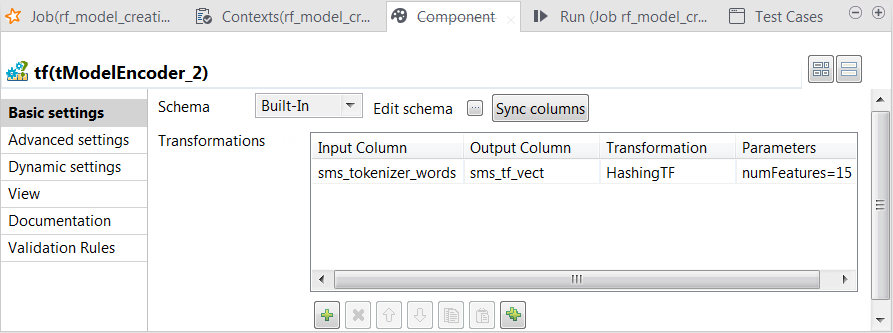
sms_tf_vect column of the Vector type to the output schema and define the transformation
as displayed in the image above.
In this transformation, tModelEncoder uses HashingTF to convert the already tokenized SMS messages into fixed-length (15 in this scenario) feature vectors to reflect the importance of a word in each SMS message.
-
Double-click the tModelEncoder
component labeled tf to open its Component view.
-
To downplay the weight of the irrelevant words in each message:
-
Double-click the tModelEncoder
component labeled tf_idf to open its Component view.
In this process, tModelEncoder reduces the weight of the words that appear very often but in too many messages, because a word like this often brings no meaningful information for text analysis, such as the word the.
-
Repeat the operations described previously over the tModelEncoder labeled
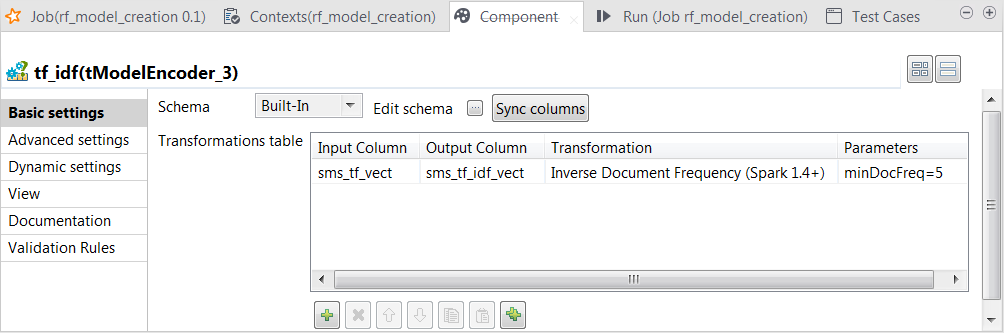
Tokenize to add the
sms_tf_idf_vect column of the Vector type to the output schema and define the
transformation as displayed in the image above.
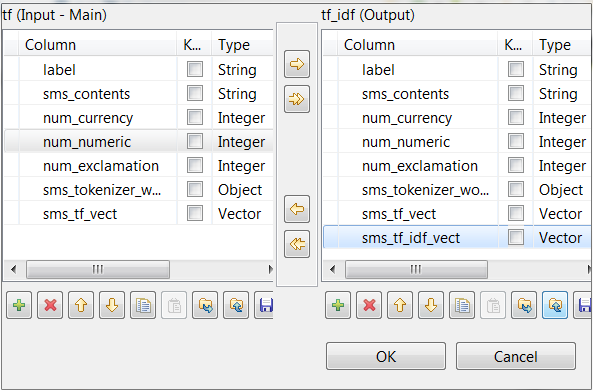
In this transformation, tModelEncoder uses Inverse Document Frequency to downplay the weight of the words that appears in 5 or more than 5 messages.
-
Double-click the tModelEncoder
component labeled tf_idf to open its Component view.
-
To combine feature vectors:
-
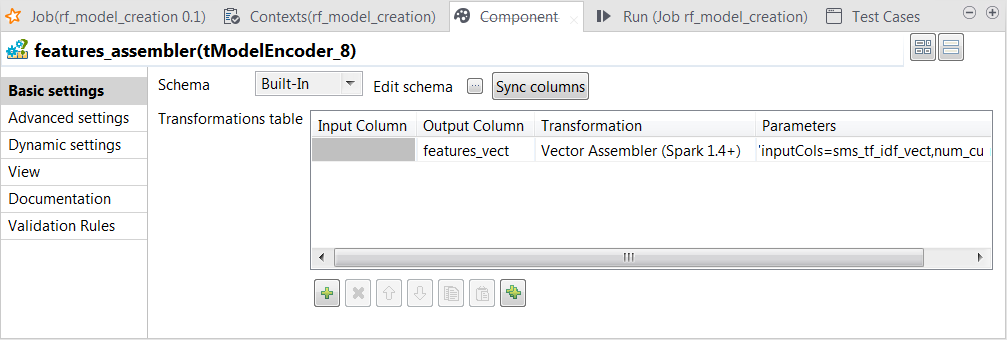
Double-click the tModelEncoder
component labeled features_assembler to open its
Component view.
-
Repeat the operations described previously over the tModelEncoder labeled Tokenizer to add the features_vect column of the
Vector type to the output schema and
define the transformation as displayed in the image above.
Note that the parameter to be put in the Parameters column is inputCols=sms_tf_idf_vect,num_currency,num_numeric,num_exclamation.
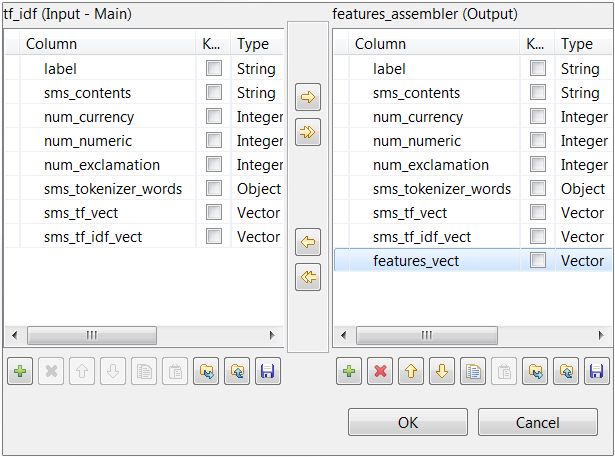 In this transformation, tModelEncoder combines all feature vectors into one single feature column.
In this transformation, tModelEncoder combines all feature vectors into one single feature column.
-
Double-click the tModelEncoder
component labeled features_assembler to open its
Component view.
Training the model using Random Forest
Procedure
-
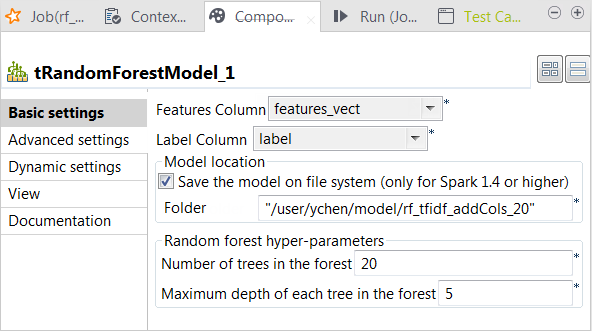
Double-click tRandomForestModel to open its
Component view.
Selecting the Spark mode
See the procedure in the Getting Started Guide.
Executing the Job to create the classification model
Procedure
Press
F6
to run this
Job.