
Trier les enregistrements d'entrée
À la fin de ce lien, le Studio Talend effectue automatiquement l'étape de re-collecte afin de grouper les résultats de l'exécution et de les passer au composant suivant.
Configurer le tSortRow
Procédure
-
Double-cliquez sur le tSortRow pour ouvrir sa vue Component.
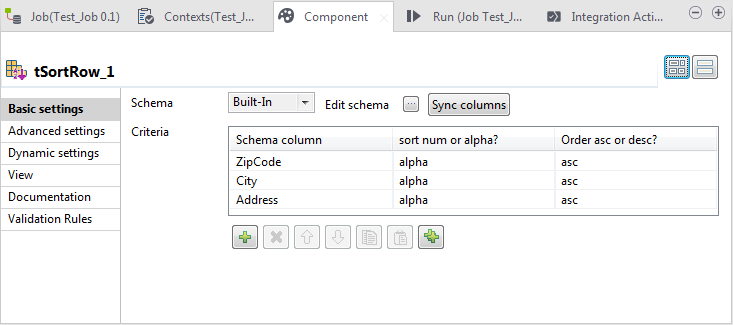
-
Sous la table Criteria (Critères), cliquez trois fois sur le bouton
 pour ajouter trois lignes à la table.
pour ajouter trois lignes à la table.
-
Cliquez sur Advanced settings pour ouvrir la vue correspondante.
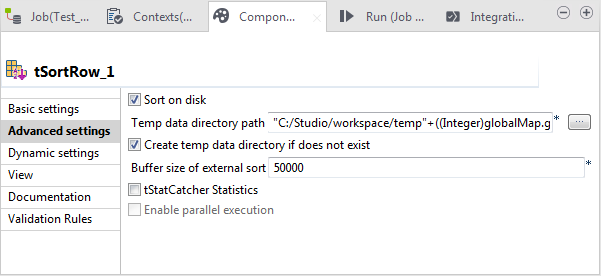
-
Dans le champ Temp data directory path, saisissez le chemin d'accès, ou parcourez votre système jusqu'au dossier dans lequel stocker les données temporaires traitées par le tSortRow. Ainsi, le tSortRow permet de traiter considérablement plus de données.
Comme les process s'écrasent s'ils sont écrits dans le même répertoire, vous devez créer le dossier pour chaque process à traiter, via l'ID du process.Pour utiliser la variable représentant l'ID du process, cliquez sur l'onglet Code afin d'ouvrir cette vue. Dans cette vue, recherchez thread_id. Dans cet exemple, la variable est tCollector_1_THREAD_ID.
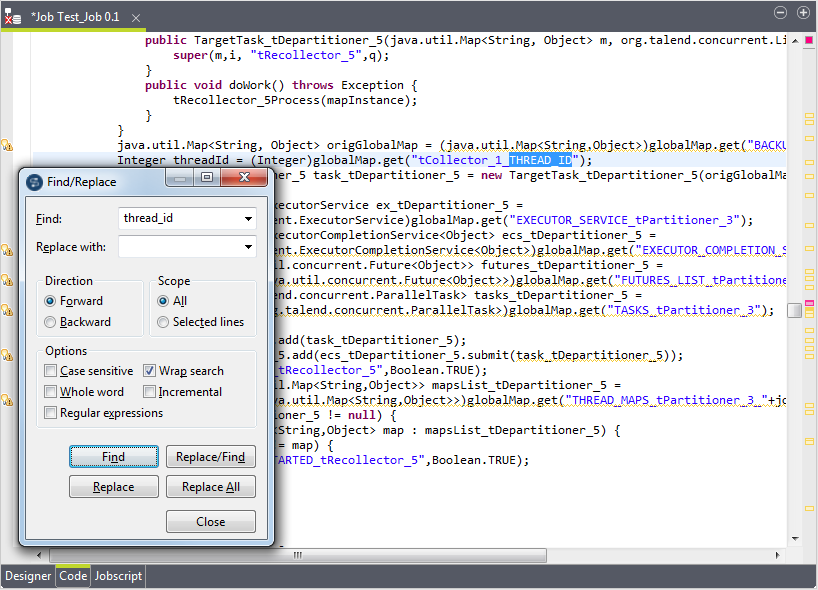 Saisissez le chemin d'accès à l'aide de la variable. Le chemin d'accès se présente comme suit :"E:/Studio/workspace/temp"+((Integer)globalMap.get("tCollector_1_THREAD_ID")).
Saisissez le chemin d'accès à l'aide de la variable. Le chemin d'accès se présente comme suit :"E:/Studio/workspace/temp"+((Integer)globalMap.get("tCollector_1_THREAD_ID")).
Configurer l'étape de dé-partitionnement
Procédure
-
Cliquez sur le lien représentant l'étape de dé-partitionnement pour ouvrir sa vue Component. Cliquez ensuite sur l'onglet Parallelization.
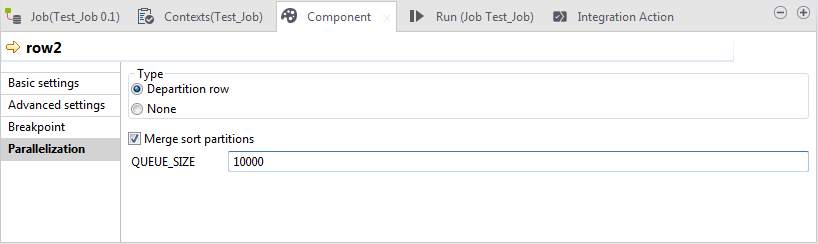 L'option Departition row a été automatiquement sélectionnée dans la zone Type. Si vous sélectionnez None, vous désactivez la parallélisation du flux de données sur ce lien. Notez que selon le lien que vous configurez, une option Repartition row peut être disponible dans la zone Type afin de re-partitionner un flux de données déjà dé-partitionné.Dans cette vue Parallelization, vous devez définir les propriétés suivantes :
L'option Departition row a été automatiquement sélectionnée dans la zone Type. Si vous sélectionnez None, vous désactivez la parallélisation du flux de données sur ce lien. Notez que selon le lien que vous configurez, une option Repartition row peut être disponible dans la zone Type afin de re-partitionner un flux de données déjà dé-partitionné.Dans cette vue Parallelization, vous devez définir les propriétés suivantes :- Buffer Size : le nombre de lignes qui sont traitées avant que la mémoire soit libérée.
- Merge sort partitions : cette option permet d'implémenter l'algorithme Mergesort afin d'assurer la cohérence des données.