
Sorting the input records
At the end of this link, Talend Studio automatically accomplishes the recollecting step to group and output the execution results to the next component.
Configuring tSortRow
Procedure
-
Double-click tSortRow to open its
Component view.
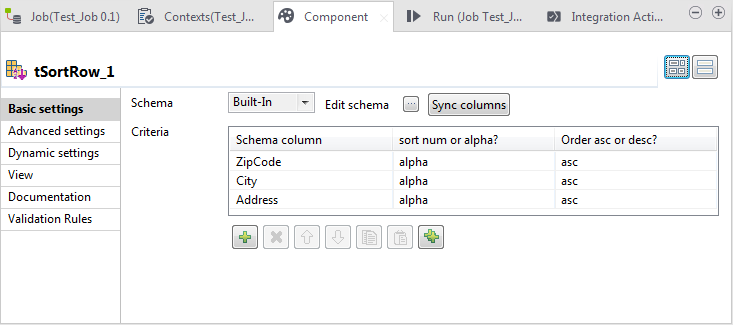
-
Under the Criteria table, click the
 button three times to add three rows to the table.
button three times to add three rows to the table.
-
Click Advanced settings to open its
view.
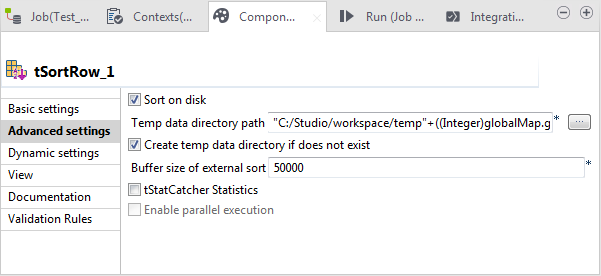
-
In Temp data directory path, enter
the path to, or browse to the folder you want to use to store the
temporary data processed by tSortRow.
In this approach, tSortRow is enabled
to sort considerably more data.
As the threads will overwrite each other if they are written in the same directory, you need to create the folder for each thread to be processed using its thread ID.To use the variable representing the thread IDs, you need to click Code to open its view and in that view, find this variable by searching for thread_id. In this example, this variable is tCollector_1_THREAD_ID.
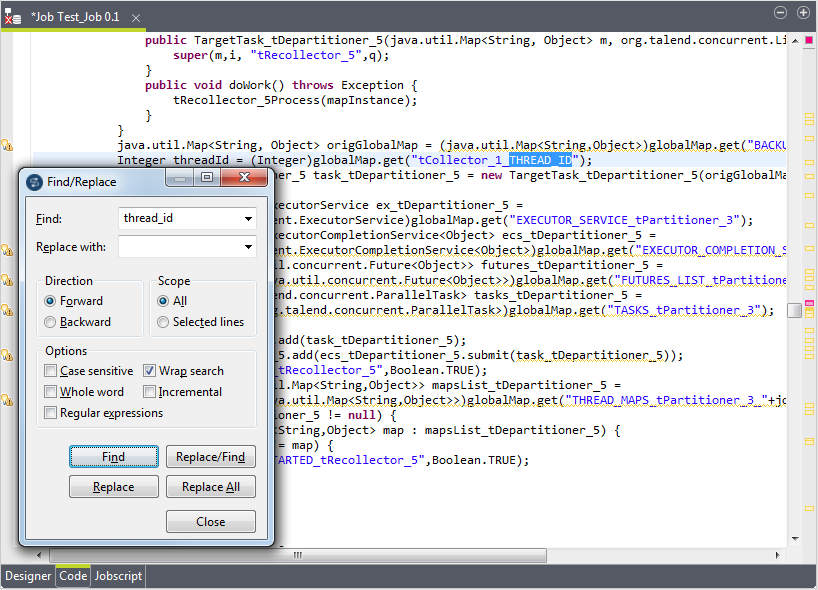 Then you need to enter the path using this variable This path reads like:"E:/Studio/workspace/temp"+((Integer)globalMap.get("tCollector_1_THREAD_ID")).
Then you need to enter the path using this variable This path reads like:"E:/Studio/workspace/temp"+((Integer)globalMap.get("tCollector_1_THREAD_ID")).
Configuring the departitioning step
Procedure
-
Click the link representing the departitioning step to open its
Component view and click the
Parallelization tab.
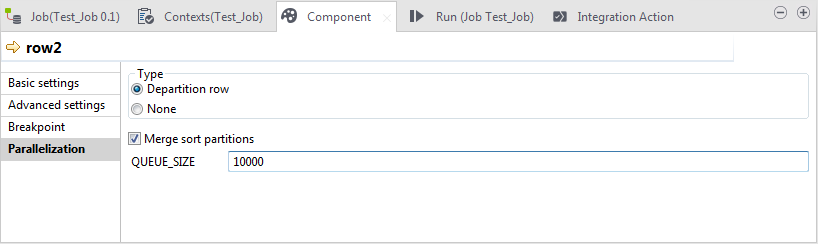 The Departition row option has been automatically selected in the Type area. If you select None, you are actually disabling parallelization for the data flow to be handled over this link. Note that depending on the link you are configuring, a Repartition row option may become available in the Type area to repartition a data flow already departitioned.In this Parallelization view, you need to define the following properties:
The Departition row option has been automatically selected in the Type area. If you select None, you are actually disabling parallelization for the data flow to be handled over this link. Note that depending on the link you are configuring, a Repartition row option may become available in the Type area to repartition a data flow already departitioned.In this Parallelization view, you need to define the following properties:- Buffer Size: the number of rows to be processed before the memory is freed.
- Merge sort partitions: this allows you to implement the Mergesort algorithm to ensure the consistency of data.