
Profiler un fichier ADLS Databricks via Hive
Depuis la perspective Profiling du Studio Talend, vous pouvez générer une analyse de colonnes sur un fichier ADLS Databricks via Hive.
- télécharger le pilote JDBC et l'ajouter au Studio Talend,
- créer une connexion JDBC au cluster ADLS,
- créer une analyse de colonnes avec des indicateurs simples sur la table et les colonnes.
Vous pouvez modifier les paramètres de l'analyse et ajouter d'autres indicateurs selon vos besoins. Vous pouvez également créer ultérieurement d'autres analyses sur ce fichier ADLS en utilisant la même table Hive.
Télécharger le pilote JDBC et l'ajouter au Studio Talend
Le pilote JDBC est un fichier Jar que vous devez créer afin de créer une connexion JDBC.
Procédure
-
Sous Talend, sélectionnez Modules et cliquez sur Open (Ouvrir).
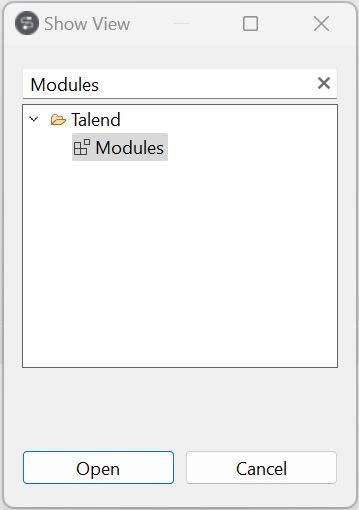
-
Dans la vue Modules, cliquez sur
 .
.
Résultats
Se connecter à un fichier ADLS Databricks Gen2
Vous devez créer une table externe et configurer un paramètre pour profiler un fichier ADLS Databricks Gen2.
Avant de commencer
Pour créer une table externe, vous pouvez utiliser les composants tAzureFSConfiguration et tJava.
Pourquoi et quand exécuter cette tâche
Procédure
Créer une connexion à un cluster Databricks ADLS
Avant de commencer
- Vous avez sélectionné la perspective Profiling .
- Vous avez suivi la procédure Télécharger le pilote JDBC et l'ajouter au Studio Talend.
Pourquoi et quand exécuter cette tâche
Procédure
Créer une analyse de profiling sur un fichier ADLS Databricks via Hive
Après avoir créé une connexion à un cluster ADLS Databricks via Hive, vous pouvez créer une analyse de profiling sur un fichier spécifique.
Avant de commencer
- Vous avez sélectionné la perspective Profiling .
- Vous avez suivi la procédure Créer une connexion à un cluster Databricks ADLS.
Pour plus d'informations concernant les analyses de colonnes, consultez Analyses de colonnes.