
Configurer l'étape de partitionnement
Procédure
-
Cliquez sur le lien représentant l'étape de partitionnement pour ouvrir sa vue Component. Cliquez ensuite sur l'onglet Parallelization.
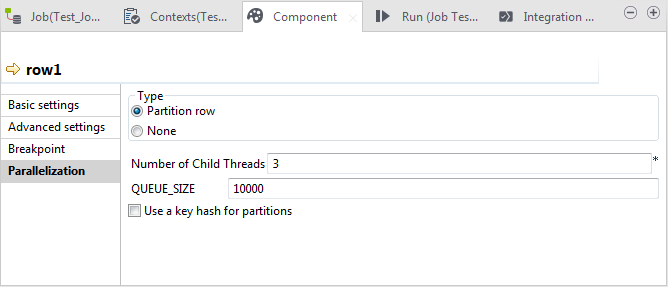 L'option Partition row a été automatiquement sélectionnée dans la zone Type. Si vous sélectionnez None, vous désactivez la parallélisation du flux de données sur ce lien. Notez que selon le lien que vous configurez, une option Repartition row peut être disponible dans la zone Type afin de re-partitionner un flux de données déjà dé-partitionné.Dans cette vue Parallelization, vous devez définir les propriétés suivantes :
L'option Partition row a été automatiquement sélectionnée dans la zone Type. Si vous sélectionnez None, vous désactivez la parallélisation du flux de données sur ce lien. Notez que selon le lien que vous configurez, une option Repartition row peut être disponible dans la zone Type afin de re-partitionner un flux de données déjà dé-partitionné.Dans cette vue Parallelization, vous devez définir les propriétés suivantes :- Number of Child Threads : le nombre de process que vous souhaitez obtenir en divisant les enregistrements d'entrée. Il est recommandé de saisir un nombre N-1 où N est le nombre total de CPU ou cœurs de la machine traitant les données.
- Buffer Size : le nombre de lignes à mettre en cache pour chacun des process générés.
- Use a key hash for partitions : cela vous permet d'utiliser le mode Hash pour répartir les enregistrements dans les process.
Une fois la case cochée, la table Key Columns s'affiche. Vous pouvez y configurer les colonnes sur lesquelles appliquer le mode Hash. Vous pouvez y configurer les colonnes sur lesquelles appliquer le mode Hash.
Si vous laissez cette case décochée le mode de répartition est Round-robin, ce qui signifie que les enregistrements sont répartis un par un dans chaque process, de manière circulaire, jusqu'à ce que le dernier enregistrement soit distribué. Ce mode ne peut garantir que les enregistrements répondant aux critères vont bien dans les mêmes process.