
Activer la parallélisation des flux de données
Dans le Studio Talend, paralléliser des flux de données signifie partitionner un flux de données d'entrée d'un sous-Job en processus parallèles et les exécuter simultanément, afin d'obtenir de meilleures performances. Ces processus sont toujours exécutés sur la même machine.
Notez que la fonctionnalité décrite dans cette section est uniquement disponible si vous avez souscrit à l'une des solutions Platform ou Big Data.
Vous pouvez utiliser des composants dédiés ou utiliser l'option Set parallelization dans le menu contextuel dans un Job afin d'implémenter ce type d'exécution parallèle.
Les composants dédiés sont le tPartitioner, le tCollector, le tRecollector et le tDepartitioner.
Les sections suivantes expliquent comment utiliser l'option Set parallelization ainsi que l'onglet vertical Parallelization associé à la connexion Row.
Vous pouvez activer ou désactiver la parallélisation en un clic. Le Studio Talend automatise ensuite l'implémentation à travers le Job.
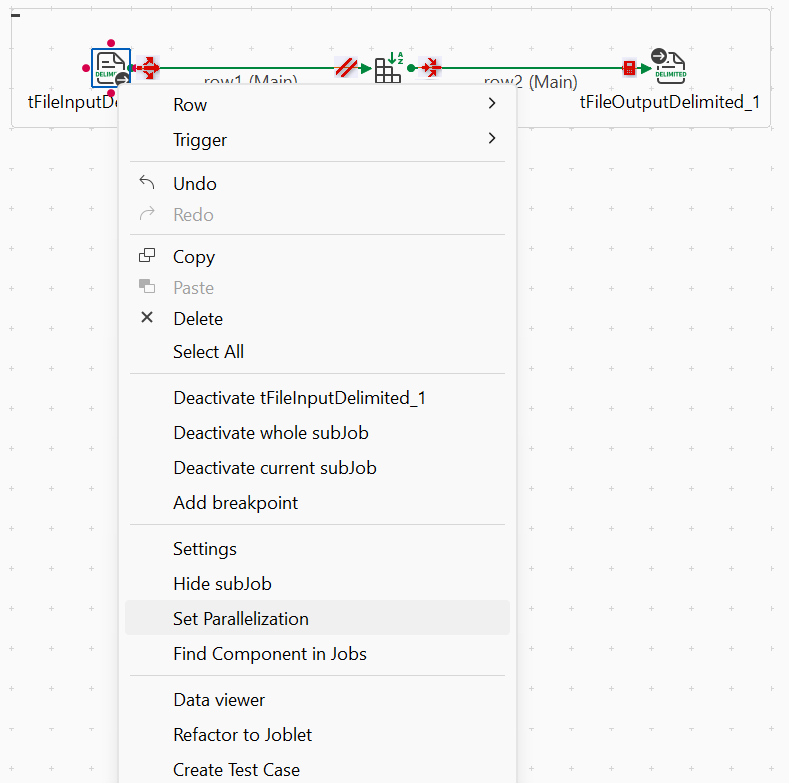
L'implémentation de la parallélisation nécessite quatre étapes clé :
- Le partitionnement (
 ) : dans cette étape, le Studio Talend partitionne les enregistrements d'entrée en un nombre donné de process.
) : dans cette étape, le Studio Talend partitionne les enregistrements d'entrée en un nombre donné de process. - La collecte (
 ) : dans cette étape, le Studio Talend collecte les process partitionnés et les envoie dans un composant donné pour traitement.
) : dans cette étape, le Studio Talend collecte les process partitionnés et les envoie dans un composant donné pour traitement. - Le dé-partitionnement (
 ) : dans cette étape, le Studio Talend regroupe les sorties des exécutions parallèles des process partitionnés.
) : dans cette étape, le Studio Talend regroupe les sorties des exécutions parallèles des process partitionnés. - La re-collecte (
 ) : dans cette étape, le Studio Talend capture les résultats des exécutions groupées et les envoie vers un composant donné.
) : dans cette étape, le Studio Talend capture les résultats des exécutions groupées et les envoie vers un composant donné.
Une fois l'implémentation automatique effectuée, vous pouvez modifier la configuration par défaut en cliquant sur la connexion correspondante entre les composants.