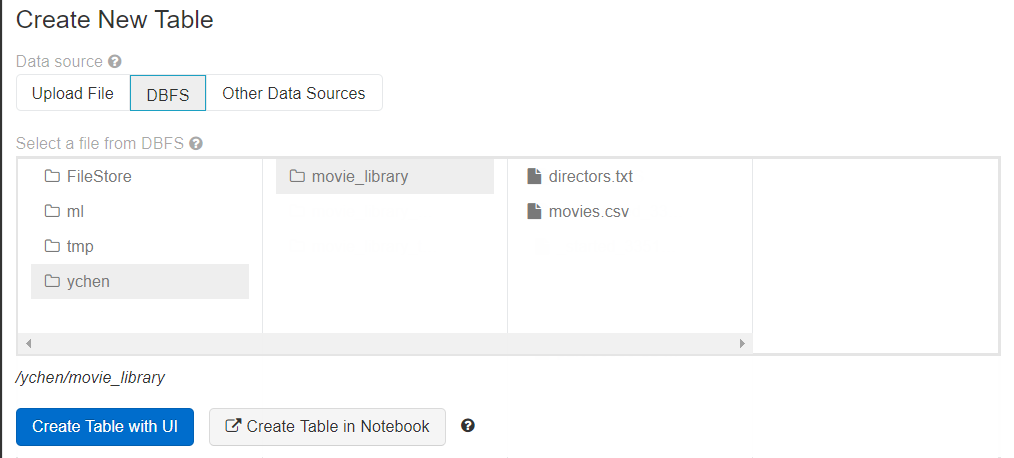
Charger des fichiers dans DBFS (Databricks File System)
Charger un fichier dans DBFS permet à des Jobs Big Data de lire et traiter ce fichier. DBFS est le système de fichiers Big Data à utiliser dans cet exemple.
Dans cette procédure, vous allez créer un Job qui écrit des données dans votre système DBFS. Pour les fichiers nécessaires à ce scénario, vous pouvez télécharger tdf_gettingstarted_source_files.zip dans l'onglet Téléchargements du panneau de gauche de cette page .
Avant de commencer
-
Vous avez démarré votre Studio Talend et ouvert la perspective Integration .
Procédure
-
Cliquez-droit sur le tDBFSConnection et, dans le menu contextuel qui s'affiche, sélectionnez .
Exemple
-
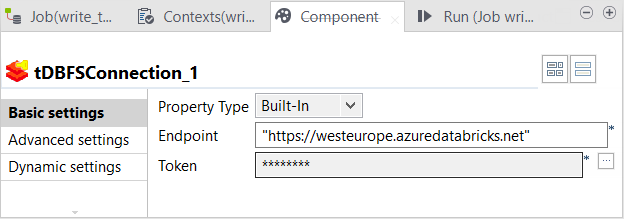
Double-cliquez sur le tDBFSConnection pour ouvrir sa vue Component.
Exemple
-
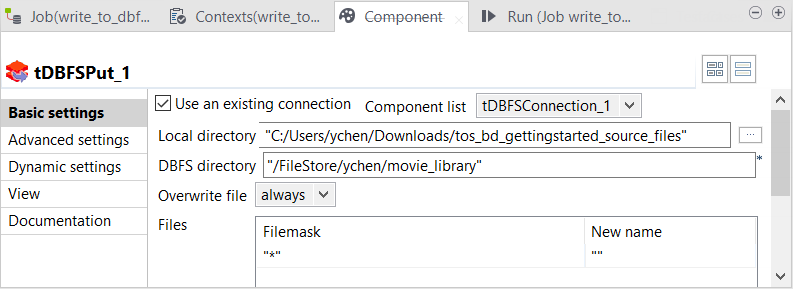
Double-cliquez sur le tDBFSPut pour ouvrir sa vue Component.
Exemple
-
Appuyez sur F6 pour exécuter le Job.
Les fichiers concernant les films et leurs cinéastes sont stockés dans ce répertoire et ouverts automatiquement. Elle affiche l'avancement de l'exécution du Job.
Résultats
Lorsque le Job est terminé, les fichiers chargés se trouvent dans DBFS, dans le répertoire spécifié.