
Nouvelles fonctionnalités
Big Data
| Fonctionnalité | Description |
|---|---|
| Support de la migration de masse des distributions Hadoop pour les Jobs Big Data | Vous pouvez à présent migrer d'un Job à l'autre la distribution d'Hadoop centralisée dans le référentiel et réutilisée dans des Jobs Big Data. Pour plus d'informations, consultez Migrer une distribution Hadoop. 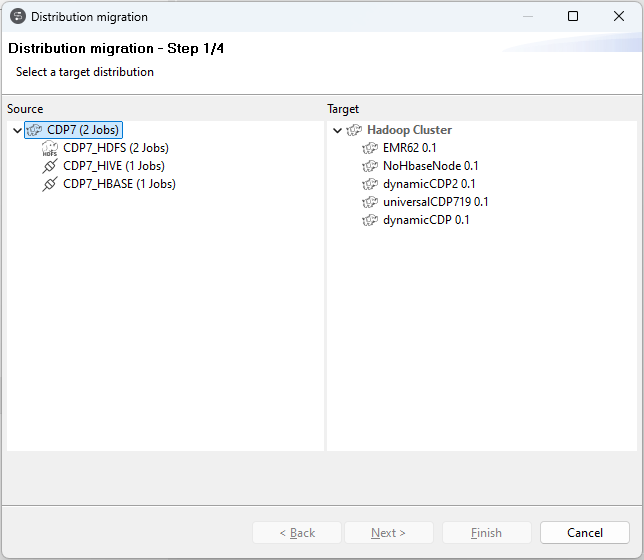 |
| Nouveaux composants MapRDB pour HPE Datafabric 7.7 dans les Jobs Standards | Les composants MapRDB suivants sont à présent disponibles dans les Jobs Standards lorsque vous utilisez un cluster HPE Datafabric 7.7 :
Les paramètres Distribution et Version ont été supprimés de la vue Basic settings (Paramètres simples). |
| Support des composants Iceberg de voyage dans le temps dans les Jobs Standards | La fonctionnalité de voyage dans le temps est à présent disponible dans le composant tIcebergInput, dans les Jobs Standards. La nouvelle case Use time travel (Utiliser le voyage dans le temps) de la vue Basic settings (Paramètres simples) vous permet de lire les données d'une table Iceberg en spécifiant un horodatage ou un ID de snapshot. Le paramètre SQL query (Requête SQL) a également été modifié. Il est à présent une case nommée Use custom SQL (Utiliser du SQL personnalisé). 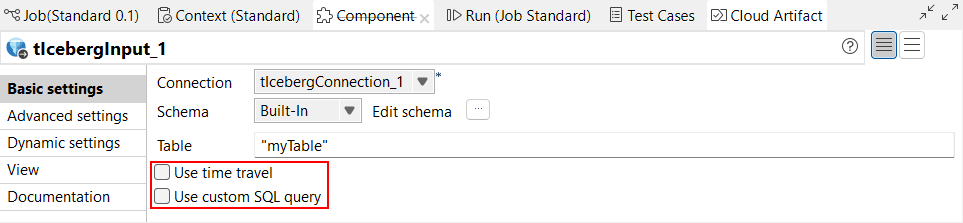 |
| Support des composants Iceberg de voyage dans le temps dans les Jobs Spark Batch | La fonctionnalité de voyage dans le temps est à présent disponible dans le composant tIcebergInput, dans les Jobs Spark Batch. La nouvelle case Use time travel (Utiliser le voyage dans le temps) de la vue Basic settings (Paramètres simples) vous permet de lire les données d'une table Iceberg en spécifiant une branche, un tag, un horodatage ou un ID de snapshot.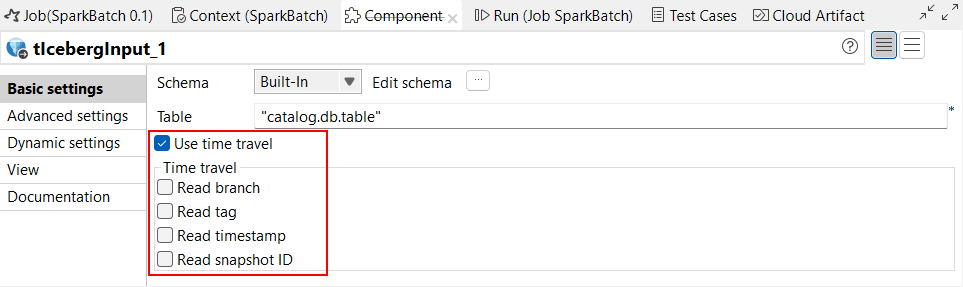 |
| Support d'Amazon EMR 7.x avec Spark Universal 3.5.x | Vous pouvez à présent exécuter vos Jobs Spark sur un cluster Amazon EMR, à l'aide de Spark Universal avec Spark 3.5.x en mode YARN cluster. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec Amazon EMR 7.x. Notez qu'un problème survient avec les Jobs contenant des composants Kinesis, avec les versions 7.x d'Amazon EMR. Lorsque vous utilisez le tKinesisInput, la sortie est vide. |
Intégration continue
| Fonctionnalité | Description |
|---|---|
|
Le Builder Talend d'intégration continue a été mis à niveau en version 8.0.19 |
Le Builder Talend d'intégration continue a été mis à niveau, passant de la version 8.0.18 à la version 8.0.19. Utilisez le Builder Talend d'intégration continue 8.0.19 dans vos commandes d'intégration continue ou dans vos scripts de pipelines, à partir de cette version mensuelle et jusqu'à la sortie d'une nouvelle version du Builder Talend d'intégration continue. |
Intégration de données
| Fonctionnalité | Description |
|---|---|
|
Nouveau composant tEmbeddingAI dans les Jobs Standards (bêta) |
Le nouveau composant tEmbeddingAI est à présent disponible dans les Jobs Standards. Il vous permet de tirer parti des modèles embarqués afin de traiter efficacement des données avec l'IA. |
|
Support de la recherche vectorielle Atlas pour les composants MongoDB dans les Jobs Standards |
Les composants MongoDB peuvent à présent utiliser les capacités de recherche vectorielle d'Atlas. |
|
Nouvelle option de personnalisation des noms d'en-têtes pour le tHTTPClient dans les Jobs Standards |
Les options Use custom authorization token header (Utiliser un en-tête de jeton d'autorisation personnalisé) et Use custom token prefix (Utiliser un préfixe de jeton personnalisé) ont été ajoutées au composant tHTTPClient et vous permettent de saisir un nom et un préfixe d'en-tête de jeton d'autorisation personnalisé lorsque vous utilisez le type d'authentification OAuth 2.0. |
|
Mise à niveau de JTOpen en version 20.x pour les composants AS400 dans les Jobs Standards |
Les composants AS400 utilisent à présent la version 20.x de la bibliothèque JTOpen. |
Data Mapper
| Fonctionnalité | Description |
|---|---|
| Nouvelles fonctions de bases de données dans les maps DSQL | Vous pouvez à présent utiliser les fonctions suivantes lorsque vous utilisez des bases de données :
|
| Support des blocs avec la clause WITH dans les maps DSQL | Vous pouvez à présent utiliser un bloc après une clause WITH. Par exemple :
|
| Support de plusieurs clés avec la clause GROUP BY dans les maps DSQL | Vous pouvez à présent utiliser une liste de clés séparées par une virgule dans la clause GROUP BY. Par exemple :
|
| Mise à jour de la syntaxe pour les littéraux de chaînes de caractères dans les maps DSQL | La syntaxe du type de données de chaîne de caractères a été mise à jour :
|
| Support de plusieurs collections après les clauses FROM et UNNEST dans les maps DSQL | Vous pouvez à présent spécifier plusieurs collections après les clauses FROM et UNNEST. Par exemple :
|
Qualité de données
| Fonctionnalité | Description |
|---|---|
| Nouveau composant de validation JSON | Vous pouvez à présent valider des colonnes JSON dans les Jobs Sandards à l'aide du composant tJSONValidator. |
| AS400 | Les versions 7R3 et supérieures sont à présent supportées. |