Utiliser des variables de contexte pour filtrer différentes données lors de l'exécution
Cloud API Services Platform
Cloud Big Data
Cloud Big Data Platform
Cloud Data Fabric
Cloud Data Integration
Cloud Data Management Platform
Cloud Pipeline Designer Standard Edition
Data Fabric
Dans ce scénario, une variable de contexte est ajoutée pour écraser la valeur utilisée pour filtrer les données utilisateur·trices lors de l'exécution.
Avant de commencer
Vous avez précédemment créé une connexion au système stockant vos données source, ici une connexion Test.
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Des données relatives à des informations utilisateur·trices, notamment des noms, entreprises, adresses e-mail, soldes de comptes etc. Pour plus d'informations, consultez Créer un jeu de données de test.
Vous avez également créé le jeu de données de test de destination pour stocker la sortie des logs.
Procédure
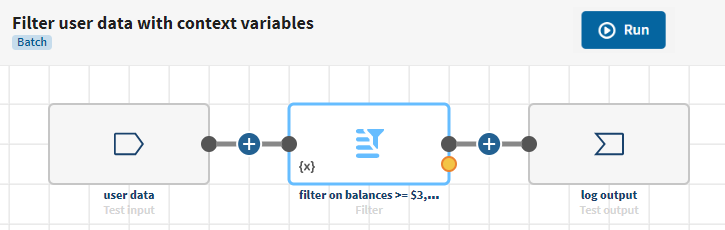
Cliquez sur Add pipeline (Ajouter un pipeline) dans la page Pipelines. Votre nouveau pipeline s’ouvre.
Donnez-lui un nom significatif.
Exemple
Filter user data with context variables
Cliquez sur ADD SOURCE pour ouvrir le panneau vous permettant de sélectionner vos données source, ici les données utilisateur·trices.
Sélectionnez votre jeu de données et cliquez sur Select (Sélectionner) pour l'ajouter au pipeline.
Renommez-le si nécessaire.
Cliquez sur le bouton et ajoutez un processeur Filter au pipeline. Le panneau de Configuration s’affiche.
Donnez un nom significatif au processeur, filter on balances >= $3,000 par exemple.
Dans la zone Filter :
Sélectionnez .balance dans la zone Input, car vous souhaitez filtrer les enregistrements correspondant aux soldes des comptes utilisateur·trices.
Sélectionnez None (Aucune) dans la liste Optionally select a function to apply (Sélectionnez une fonction facultative à appliquer), >= dans la liste Operator (Opérateur) et saisissez $3,000 dans la liste Value (Valeur) puisque vous souhaitez filtrer sur les utilisateurs et utilisatrices ayant un solde de compte supérieur ou égal à 3 000 dollars.
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
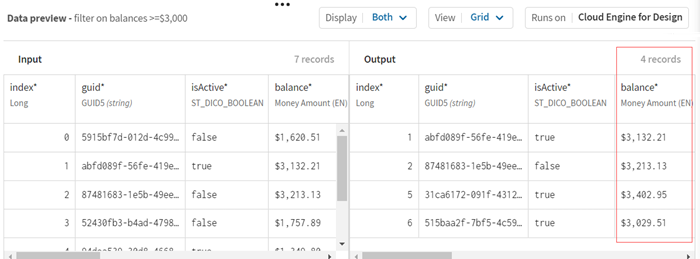
Vous pouvez voir que les enregistrements sont filtrés et que seuls quatre enregistrements répondent aux critères définis :
Cliquez sur l'élément ADD DESTINATION du pipeline pour ouvrir le panneau vous permettant de sélectionner le jeu de données qui contiendra les données filtrées.
Donnez un nom significatif à la Destination, log output par exemple.
Dans l'onglet Configuration du jeu de données de destination, activez l'option Log records to STDOUT pour afficher les enregistrements en lecture dans les logs d'exéuction du pipeline.
(Facultatif) Si vous exécutez votre pipeline à cette étape, vous pouvez voir dans les logs que les quatre enregistrements vus dans l'aperçu des données sont passés, selon le filtre défini :
Retournez dans l'onglet Configuration du processeur Filter pour ajouter et attribuer une variable :
Cliquez sur l'icône près du champ Value (Valeur) pour ouvrir la fenêtre Assign a variable (Attribuer une variable).
Cliquez sur Add variable (Ajouter une variable).
Nommez votre variable, balance_amount par exemple.
Saisissez la valeur de la variable qui écrasera la valeur par défaut, ici $1,000.
Saisissez une description si nécessaire et cliquez sur Add (Ajouter).
Une fois votre variable créée, vous êtes redirigé·e vers la fenêtre Assign a variable listant toutes les variables de contexte. Sélectionnez vos variables et cliquez sur Assign (Attribuer).
Votre variable et sa valeur sont attribuées au champ Value du filtre, ce qui signifie que la valeur de $1,000 écrase celle de $3,000 précédemment définie.
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
Dans la barre d'outils en haut de Talend Cloud Pipeline Designer, cliquez sur le bouton Run (Exécuter) pour ouvrir le panneau vous permettant de sélectionner votre profil d'exécution.
Sélectionnez dans la liste votre profil d'exécution (pour plus d'informations, consultez Profils d'exécution), puis cliquez sur Run (Exécuter) pour exécuter votre pipeline.
Résultats
Votre pipeline est en cours d'exécution, les données sont filtrées selon la variable de contexte attribuée à la valeur de filtre. Dans les logs d'exécution du pipeline, vous pouvez voir :
la valeur de variable de contexte utilisée lors de l'exécution
le nombre d'enregistrements produits, ici 7 enregistrements répondent aux critères, ce qui signifie que 7 enregistrements utilisateur ont un solde de compte supérieur ou égal à mille dollars
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.

 et ajoutez un processeur Filter au pipeline. Le panneau de Configuration s’affiche.
et ajoutez un processeur Filter au pipeline. Le panneau de Configuration s’affiche.


 près du champ Value (Valeur) pour ouvrir la fenêtre Assign a variable (Attribuer une variable).
près du champ Value (Valeur) pour ouvrir la fenêtre Assign a variable (Attribuer une variable).


