
Indexer des données nettoyées et dédoublonnées dans Elasticsearch
Avant de commencer
-
Le cluster Elasticsearch et le front-end Elasticsearch-head doivent être lancés avant l'exécution du Job.
Pour plus d'informations sur Elasticsearch-head, qui est un plug-in utilisé pour parcourir un cluster Elasticsearch, consultez https://mobz.github.io/elasticsearch-head/ (en anglais).
Procédure
-
Double-cliquez sur le tMatchIndex pour afficher sa vue Basic settings et définissez les propriétés du composant.
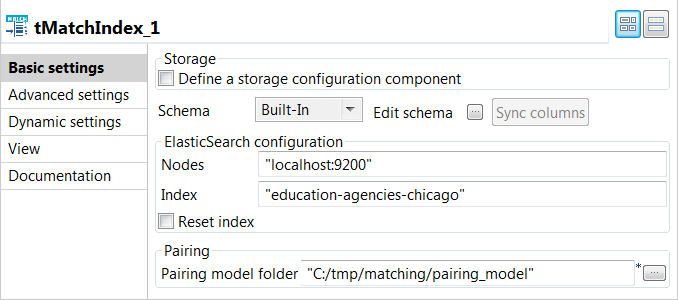
Résultats
Le tMatchIndex a créé l'index education-agencies-chicago dans Elasticsearch, l'a alimenté avec les données nettoyées et a calculé les meilleurs suffixes basés sur les valeurs des clés de bloc.
Vous pouvez utiliser le plug-in Elasticsearch-head afin de parcourir l'index créé par le tMatchIndex.


Vous pouvez maintenant utiliser les données indexées en tant que jeu de données de référence avec le composant tMatchIndexPredict.
Pour un exemple de rapprochement continu, consultez Rapprochement continu à l'aide du tMatchIndexPredict.