
Elasticsearchでクリーンで重複除去済みのデータをインデックス化する
始める前に
-
ElasticsearchクラスターとElasticsearchヘッドは、ジョブ実行前に開始されます。
Elasticsearchクラスターを参照するためのプラグインであるElasticsearchヘッドの詳細は、https://mobz.github.io/elasticsearch-head/をご覧ください。
手順
-
tMatchIndexコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、そのプロパティを定義します。
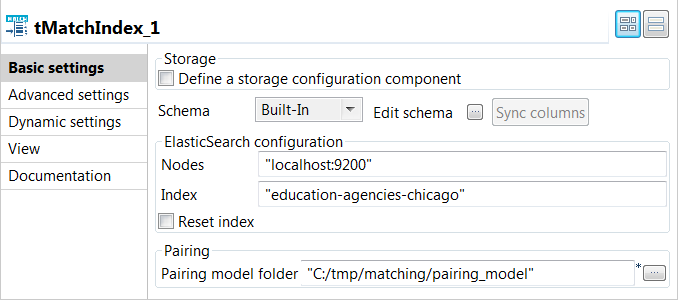
タスクの結果
tMatchIndexによって、Elasticsearch内にeducation-agencies-chicagoインデックスが作成され、クリーンなデータが入力され、ブロッキングキーの値をベースに最適なサフィックスが計算されました。
プラグインのElasticsearchヘッドを使用して、tMatchIndexによって作成されたインデックスを参照できます。


これで、インデックスが作成されたデータをtMatchIndexPredictコンポーネントの参照データセットとして使用できるようになりました。
連続マッチングを行う方法の例は、tMatchIndexPredictを使用して継続的マッチングを行うを参照してください。