
Découvrir des types sémantiques
La découverte de données calcule combien de valeurs correspondent à chaque type sémantique et, si le résultat est supérieur à 40 %, elle attribue le type sémantique à la colonne.
Lorsqu'aucun type sémantique n'obtient plus de 40 %, la découverte des données attribue un type de données (data type).
Pour afficher le pourcentage de chaque type sémantique, dans la vue de l'échantillon de votre jeu de données, cliquez sur l'icône ![]() .
.
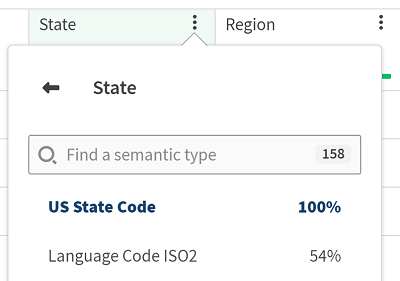
Cette fonctionnalité est également disponible depuis la vue Hierarchy (Hiérarchie).

Comment le pourcentage est-il calculé ?
-
Un pourcentage représente le nombre de valeurs correspondant au type sémantique ; jusqu'à 100 % alloués.
Pour déterminer si une valeur correspond à un type sémantique, la découverte de données dépend du type du type sémantique :
- Dictionnaire : La valeur correspond-elle à une valeur du dictionnaire ? La ponctuation, la casse, les espaces et les accents sont ignorés.
- Regular expression (Expression régulière) : La valeur correspond-elle à l'expression régulière ?
- Compound (Composé·e) : La valeur est-elle découverte dans au moins un enfant ?Un type composé est un groupe de types sémantiques existants, appelés enfants.
Si la réponse est positive, la valeur est considérée comme valide.
- L'autre pourcentage représente la similarité entre le nom de colonne et le nom du type sémantique ; jusqu'à 10 % alloués. Pour comparer les noms :Le pourcentage maximal est de 100 %. Si toutes les valeurs correspondent à un type sémantique et que le nom de colonne est identique au nom du type sémantique, le résultat est toujours de 100 %.
- C'est l'algorithme de Levenshtein qui est utilisé. Il calcule le nombre minimal de modifications (insertions, suppressions ou substitutions) nécessaires à la transformation d'une chaîne de caractères en une autre.
- La casse et les accents sont ignorés.
- Si les chaînes de caractères contiennent des espaces, l'ordre des mots est ignoré. Par exemple, US Phone et Phone US sont considérés comme identiques.
Afficher la barre de statistiques
La barre de statistiques affiche le nombre de valeurs invalides, vides et valides selon le type sémantique assigné. Pour l'afficher, activez le paramètre Use for validation (Utiliser pour la validation) dans la configuration du type sémantique.
- Depuis la vue Grid (Grille) :

- Depuis la vue Hierarchy (Hiérarchie) :

Le pourcentage de valeurs valides peut être inférieur à celui de la découverte de données. Cela se produit lorsque :
- la règle de validation est plus restrictive que le type sémantique. Dans ce cas, les valeurs correspondent aux valeurs du type sémantique, mais, depuis la règle de validation, les valeurs ne correspondent pas, par exemple sur la casse ou la ponctuation.
- La similarité entre le nom de la colonne et le nom du type sémantique augmente le résultat du type sémantique à 100 %. Dans ce cas, la barre de statistiques affiche entre 90 % et 100 % de valeurs valides.
Découvrir des types de données
Au lieu des types sémantiques, les types de données peuvent être attribués. Si aucun type sémantique n'obtient plus de 40 %, la découverte des données attribué un type de données (data type).
- La valeur est-elle vide ?
- La valeur du type est-elle boolean (booléen) ? true et false sont les seules valeurs considérées comme type boolean (booléen).
- La valeur du type est-elle integer (entier) ?
- La valeur du type est-elle decimal (décimal) ?
- La valeur du type est-elle date ?
- Si la valeur n'est pas l'un des types ci-dessus, elle est considérée comme une valeur text (texte).
Comme la vérification est incrémentale, une valeur est toujours d'un seul type. Par exemple, la valeur 5 est de type integer (entier). Elle ne sera pas considérée comme type text (texte).