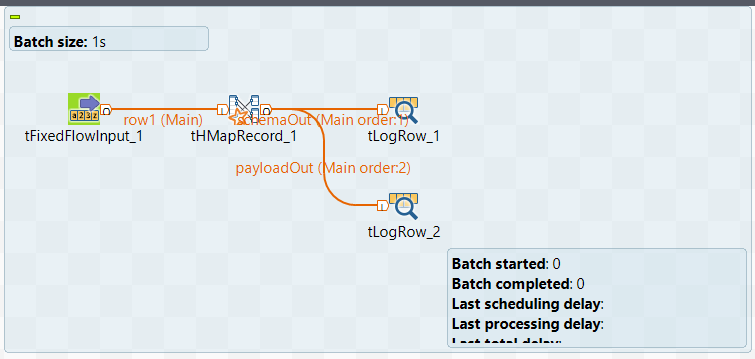
In the Studio, create a Big Data Streaming Job with one input payload
(which will be of XML representation), one schema output, one payload output (which will be
of XML representation), and the tHMapRecord.
Procedure
Navigate to Job Designs > Big Data Streaming and create a job:
Connect the components using Row > Main connection. Enter schemaOut and
payloadOut respectively, when prompted for the output
name.
Select tFixedFlowInput to edit the schema.
Add a new column pOut of String type.
Click OK.
Select the first tLogRow to edit the schema.
Add two columns, a and b,
of String type.
Click OK.
Click Sync columns.
Select the second tLogRow to edit the schema.
Add a column of String type.
Click OK.
Click Sync columns.
Double-click the tHMapRecord component to configure the
structure.
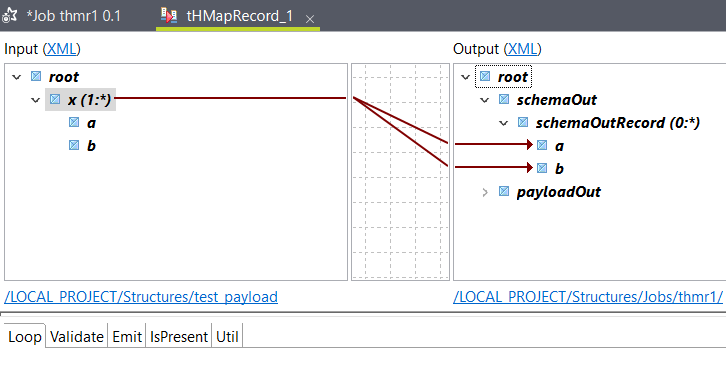
For the row1 input connection, select the a payload
structure from the wizard with an XML representation.
For the payloadOut output connection, select a payload
structure from the wizard with an XML representation.
Talend Data Mapper automatically generates
the corresponding structure of the schemaOut output connection because
it has multiple columns. When you configure the payload structures,
Talend Data Mapper automatically creates a
map with a new multi-output or wrapper structure, which contains the
selected payloadOut structure and a generated structure of AVRO
representation for the schemaOut connection.
The tHMapRecord map view opens.
Map the input elements to the output elements:
The input payload structure has an XML representation, while the multi-output
or wrapper structure uses the first structure representation of the payload
connection, which is XML in this case.
Run the job.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – please let us know!