
Top() utvärderar ett uttryck på den första (översta) raden i ett kolumnsegment i en tabell. Vilken rad som den beräknas för beror på värdet för offset, om sådant finns, standardvärdet är raden högst upp. För diagram som inte är tabeller görs Top()-utvärderingen på den första raden i den aktuella kolumnen i diagrammets raka tabellmotsvarighet.
Syntax:
Top([TOTAL] expr [ , offset [,count ]])
Returnerad datatyp: dual
Argument:
| Argument | Beskrivning |
|---|---|
| expr | Det uttryck eller fält som innehåller de data som ska mätas. |
| offset |
Om en startpunkt, offset, på n större än 1 anges flyttas utvärderingen av uttrycket n rader nedanför den översta raden. Anges ett negativt värde för startpunkten gör det att Top-funktionen fungerar likadant som Bottom-funktionen med motsvarande positivt värde för startpunkten. |
| count | Om en tredje parameter, count, anges till större än 1, returnerar funktionen ett intervall av count-värden, ett för var och en av de sista count-raderna i det aktuella kolumnsegmentet. I denna form kan funktionen användas som argument i någon av de speciella intervallfunktionerna. Intervallfunktioner |
| TOTAL |
Om tabellen är endimensionell eller om kvalificeraren iTOTAL används som argument, motsvarar det aktuella kolumnsegmentet alltid hela kolumnen. |
Begränsningar:
-
Rekursiva anrop returnerar NULL.
-
Sortering på y-värden i diagram, eller sortering efter uttryckskolumner i tabeller, är inte tillåtet när denna diagramfunktion används i något av diagrammets uttryck. Dessa sorteringsalternativ är därför automatiskt inaktiverade. När du använder den här diagramfunktion i en visualisering eller tabell kommer sorteringen av visualiseringen att återgå till den sorterade inmatningen av den här funktionen.
Exempel och resultat:
Exempel: 1
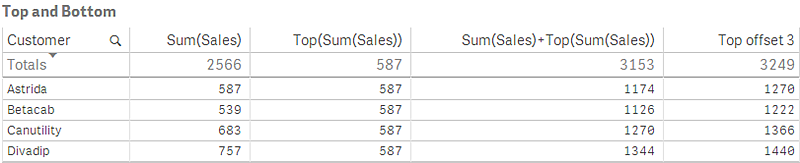
I skärmdumpen av tabellen som visas i det här exemplet skapas tabellvisualiseringen från dimensionen Customer och måtten Sum(Sales) och Top(Sum(Sales)).
Kolumnen Top(Sum(Sales)) returnerar 587 för alla rader eftersom det är värdet för den översta raden: Astrida
Tabellen visar även mer komplexa mått: ett skapat av Sum(Sales)+Top(Sum(Sales)) och ett med etiketten Top offset 3, som skapas med hjälp av uttrycket Sum(Sales)+Top(Sum(Sales), 3) och vars argument offset är angivet som 3. Det lägger till Sum(Sales)-värdet för den aktuella raden till värdet från raden tre rader nedanför den översta raden, d.v.s. den aktuella raden plus värdet för Canutility.
Exempel: 2
I tabellerna i skärmdumparna har fler dimensioner lagts till i visualiseringarna: Month och Product. För diagram med flera dimensioner beror resultatet för uttryck som innehåller funktionerna Above, Below, Top och Bottom på den ordning i vilken kolumndimensionerna sorteras av Qlik Sense. Qlik Sense evaluerar funktionerna baserat på de kolumnsegment som är resultatet från den dimension som kommer sist i sorteringsordningen. Sorteringsordningen för kolumner styrs från egenskapspanelen under Sortering. Den motsvarar inte nödvändigtvis den ordning i vilken kolumnerna visas i en tabell.
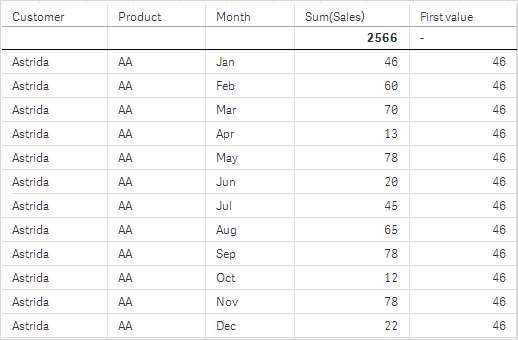
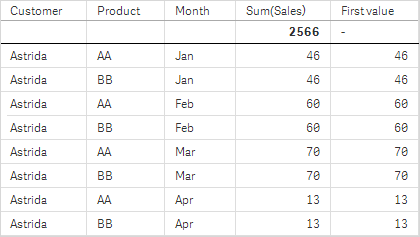
Se Exempel: 2 i funktionen Above för mer information.
|
Exempel: 3 |
Resultat | ||
|---|---|---|---|
|
Funktionen Top kan användas som indata för intervallfunktionerna. Till exempel: RangeAvg (Top(Sum(Sales),1,3)). |
I argumenten för funktionen Top(), offset inställd på 1 och count är inställd på 3. Funktionen hittar resultatet för uttrycketSum(Sales) på de tre raderna som börjar med raden under den nedersta raden i kolumnsegmentet (eftersom offset=1) och de två raderna under den (där det finns en rad). De här tre värdena används som indata för funktionen RangeAvg() som räknar ut medelvärdet för ett angivet talintervall. En tabell med Customer som dimension ger följande resultat för uttrycket RangeAvg(). |
||
|