
Функция Top() оценивает выражение в первой (верхней) строке сегмента столбца в таблице. Строка, для которой выполняется вычисление, зависит от значения элемента offset, если таковой имеет место, по умолчанию принимается верхняя строка. Для диаграмм, за исключением таблиц, функция Top() используется для оценки в первой строке текущего столбца в эквиваленте прямой таблицы диаграммы.
Синтаксис:
Top([TOTAL] expr [ , offset [,count ]])
Возвращаемые типы данных: двойное значение
Аргументы:
| Аргумент | Описание |
|---|---|
| expr | Выражение или поле, содержащее данные для измерения. |
| offset |
Если задать значение offset элемента n больше 1, можно будет переместить оценку выражения n по строкам ниже верхней строки. Если задать отрицательное число смещения, функция Top будет работать как функция Bottom с соответствующим положительным числом смещения. |
| count | Если задать для третьего параметра count значение больше 1, функция вернет ряд значений элемента count: по одному для каждой последней строки элемента count текущего сегмента столбца. В данной форме функция может использоваться в качестве аргумента для любой специальной функции интервала. Функции над выборкой |
| TOTAL |
Если таблица имеет одно измерение, или если в качестве аргумента используется префикс TOTAL, текущий сегмент столбца всегда равен всему столбцу. |
Ограничения:
-
Рекурсивные вызовы возвращают значение NULL.
-
Сортировка по значениям y на диаграммах или сортировка по столбцам выражений в таблицах не допускается, если в любом из выражений диаграммы используется эта функция диаграмм. Данные возможности сортировки автоматически отключаются. Когда используется эта функция диаграмм в визуализации или таблице, сортировка визуализации будет возвращена к сортировке на входе этой функции.
Примеры и результаты:
Пример: 1
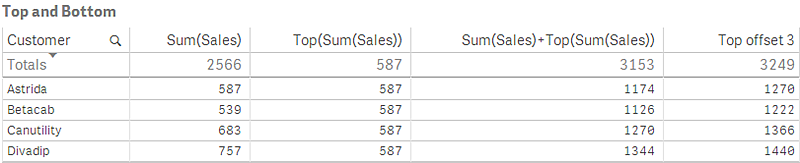
На снимке таблицы, показанной в этом примере, визуализация таблицы создана из измерения Customer и мер: Sum(Sales) и Top(Sum(Sales)).
Столбец Top(Sum(Sales)) возвращает значение 587 для всех строк, поскольку это значение верхней строки: Astrida.
В таблице также показаны более сложные меры: одна, созданная из элемента Sum(Sales)+Top(Sum(Sales)), а другая, помеченная как Top offset 3, созданная с помощью выражения Sum(Sales)+Top(Sum(Sales), 3), и имеющая аргумент offset, установленный на 3. Таким образом добавляется значение Sum(Sales) для текущей строки к значению из третьей строки от верхней строки, т. е. текущая строка плюс значение для элементаCanutility.
Пример: 2
На снимках таблиц, показанных в этом примере, к визуализациям добавлено больше измерений: Month и Product. Для диаграмм с несколькими измерениями результаты выражений, содержащих функции Above, Below, Top и Bottom, зависят от порядка, в котором измерения столбцов сортируются Qlik Sense. Программа Qlik Sense оценивает функции на основе сегментов столбца, полученных из измерения, отсортированного последним. Контроль за порядком сортировки столбцов осуществляется на панели свойств под элементом Сортировка. Этот порядок не обязательно соответствует порядку отображения столбцов в таблице.
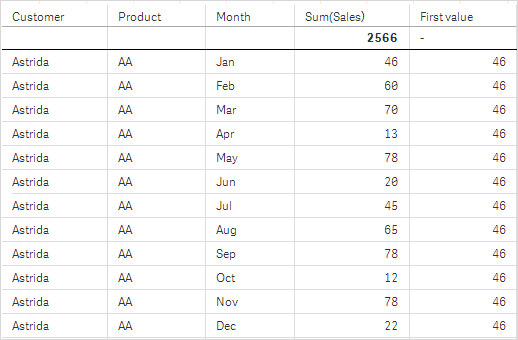
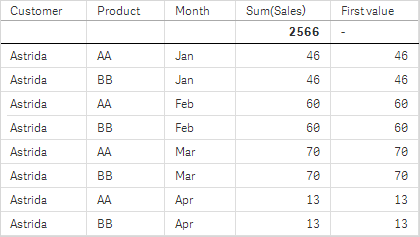
Дополнительную информацию см. в примере 2 для функции Above.
|
Пример: 3 |
Результат | ||
|---|---|---|---|
|
Функцию Top можно использовать как ввод в функции над выборкой. Например, элемент RangeAvg (Top(Sum(Sales),1,3)). |
В аргументах для функции Top() для элемента offset задано значение 1, а для элемента count задано значение 3. Функция находит результаты выражения Sum(Sales) в трех строках, начиная со строки под нижней строкой в сегменте столбца (поскольку offset=1), и в двух строках под ней (если есть строка). Эти три значения используются как ввод в функцию RangeAvg(), которая находит среднее значение в предоставленном диапазоне чисел. Таблица с элементом Customer в виде измерения выдает следующие результаты для выражения RangeAvg(). |
||
|