
In-Memory-Modell
Im Qlik Sense-In-Memory-Modell werden alle eindeutigen Werte in den im Ladeskript aus einer Tabelle ausgewählten Feldern in Feldstrukturen und die zugeordneten Daten gleichzeitig in die Tabelle geladen. Die Felddaten und die zugeordneten Daten bleiben alle im Speicher.
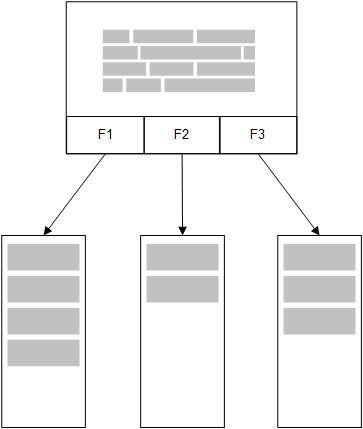
Eine zweite, betreffende Tabelle, die in den Speicher geladen wurde, würde ein gemeinsames Feld teilen und diese Tabelle könnte zum gemeinsamen Feld neue eindeutige Werte hinzufügen oder bestehende Werte teilen.
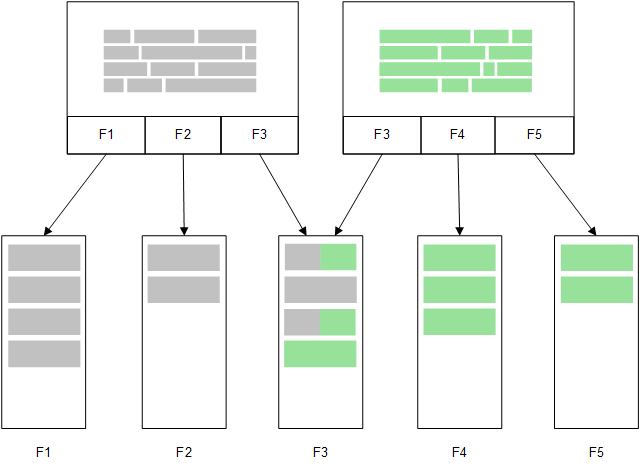
Direct Discovery
Wenn Tabellenfelder mit einem Direct Discovery LOAD-Befehl geladen werden (Direct Query), wird eine ähnliche Tabelle nur mit den DIMENSION-Feldern erstellt. Wie bei den im Speicher befindlichen Feldern werden die eindeutigen Werte für die DIMENSION-Felder in den Speicher geladen. Aber die Verknüpfungen zwischen den Feldern werden in der Datenbank belassen.
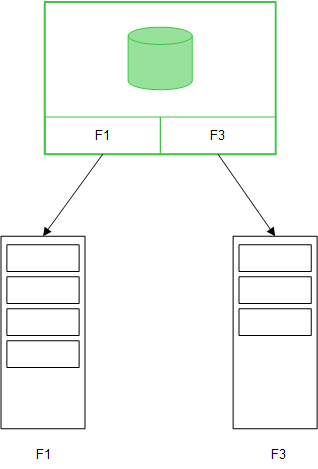
MEASURE-Feldwerte werden auch in der Datenbank belassen.
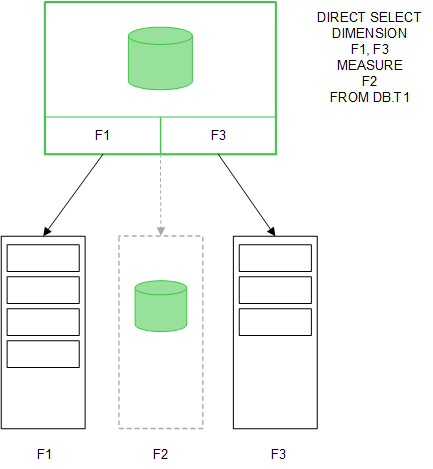
Nachdem die Struktur von Direct Discovery festgelegt wurde, können Direct Discovery-Felder mit bestimmten Visualisierungsobjekten verwendet werden, auch für Verknüpfungen mit im Speicher befindlichen Feldern. Wenn ein Direct Discovery-Feld verwendet wird, erstellt Qlik Sense automatisch die geeignete SQL-Abfrage für die externe Datenquelle. Bei Auswahlen werden die verknüpften Datenwerte der Direct Discovery-Felder in den WHERE-Bedingungen der Datenbankabfragen verwendet.
Für jede Auswahl werden die Visualisierungen mit Direct Discovery-Feldern neu berechnet, wobei die Berechnungen in der Tabelle der Quelldatenbank durch Ausführen der von Qlik Sense erstellten SQL-Abfrage ablaufen. Die Funktion der Berechnungsbedingung kann zur Angabe, wann Visualisierungen neu berechnet werden sollen, verwendet werden. Solange die Bedingung nicht erfüllt wird, sendet Qlik Sense keine Abfragen zur Neuberechnung der Visualisierungen.
Leistungsunterschiede zwischen im Speicher befindlichen und Direct Discovery-Feldern
Die Verarbeitung im Speicher ist stets schneller als in Quelldatenbanken. Die Leistung von Direct Discovery spiegelt die Leistung des Datenbanksystems wider, das die Direct Discovery-Abfragen verarbeitet.
Es ist möglich, eine Standarddatenbank und beste Praktiken zur Abfragenanpassung für Direct Discovery zu verwenden. Alle Leistungsanpassungen sollten in der Quelldatenbank erfolgen. Direct Discovery bietet keine Unterstützung für die Leistungsanpassung von Abfragen durch die Qlik Sense-App. Mithilfe der Verbindungspooling-Funktion ist es jedoch möglich, asynchrone, parallele Abrufe aus der Datenbank durchzuführen. Die Syntax des Ladeskripts zur Einrichtung der Pooling-Funktion ist:
SET DirectConnectionMax=10;
Qlik Sense-Caching verbessert auch das gesamte Nutzererlebnis. Siehe Abbildung unten (Caching und Direct Discovery)
Die Leistung von Direct Discovery mit DIMENSION-Feldern kann ebenso durch Trennen der Verknüpfung einiger Felder verbessert werden. Dies wird mit dem Schlüsselwort DETACH in DIRECT QUERY vorgenommen. Während getrennte Felder nicht nach Verknüpfungen abgefragt werden, sind sie immer noch Bestandteil der Filter, wodurch sich Auswahlzeiten verkürzen.
Alle Daten der im Speicher befindlichen Qlik Sense-Felder und Direct DiscoveryDIMENSION-Felder sind zwar im Speicher enthalten, die Weise, wie sie geladen werden, wirkt sich jedoch auf die Ladegeschwindigkeit in den Speicher aus. Qlik Sense-In-Memory-Felder speichern nur eine Kopie eines Feldwerts, wenn es mehrere Instanzen des gleichen Werts gibt. Jedoch werden alle Felddaten geladen und die duplizierten Daten dann aussortiert.
DIMENSIONFelder speichern auch nur eine Kopie eines Feldwerts, aber die duplizierten Werte werden in der Datenbank aussortiert, bevor sie in den Speicher geladen werden. Wenn Sie mit großen Datenmengen zu tun haben, wie gewöhnlich bei der Verwendung von Direct Discovery, werden die Daten durch eine DIRECT QUERY viel schneller geladen als durch das für im Speicher befindliche Felder SQL SELECT.
Unterschiede zwischen Daten im Speicher und Datenbankdaten
DIRECT QUERY berücksichtigt Groß- und Kleinschreibung, wenn Verknüpfungen mit im Speicher befindlichen Daten vorgenommen werden. Direct Discovery wählt Daten aus Quelldatenbanken in Übereinstimmung mit der Groß-/Kleinschreibung der abgefragten Datenbankfelder aus. Wenn bei den Datenbankfeldern die Groß-/Kleinschreibung nicht berücksichtigt wird, gibt eine Direct Discovery-Abfrage möglicherweise Daten zurück, die eine Abfrage im Speicher nicht ergeben würde. Zum Beispiel, wenn sich die folgenden Daten in einer Datenbank befinden, die nicht Case-sensitiv ist, ergäbe eine Direct Discovery-Abfrage des Werts "Red" alle vier Reihen.
| Spalte A | Spalte B |
|---|---|
| rot | eins |
| Rot | zwei |
| rOT | drei |
| ROT | vier |
Eine Auswahl von "Red," im Speicher ergäbe hingegen nur:
Red two
Qlik Sense normalisiert Daten in einem Ausmaß, das Treffer zu ausgewählten Daten erzeugt, die Datenbanken nicht zuordnen würden. Als Folge kann eine Abfrage im Speicher mehr passende Werte ergeben als eine Direct Discovery-Abfrage. Zum Beispiel unterscheiden sich in der folgenden Tabelle die Werte für die Zahl "1" nach der Position der Leerzeichen um sie:
| Spalte A | Spalte B |
|---|---|
| ' 1' | Leerzeichen vorher |
| '1' | Kein Leerzeichen |
| '1 ' | Leerzeichen danach |
| '2' | zwei |
Wenn Sie "1" in einem Filterfenster für ColumnA auswählen, wo sich die Daten im standardmäßigen Qlik Sense--In-Memory befinden, werden die ersten drei Reihen zugeordnet:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
Wenn das Filterfenster Direct Discovery-Daten enthält, verknüpft die Auswahl von "1" möglicherweise nur "no_space". Die sich für Direct Discovery-Daten ergebende Treffer hängen von der Datenbank ab. Einige ergeben nur "no_space" und andere, wie SQL Server, ergeben "no_space" und "space_after".
Caching und Direct Discovery
Qlik Sense-Caching speichert Auswahlstatus von Abfragen und zugeordnete Abfrageergebnisse im Speicher. Bei gleichen Arten von Auswahlen verwendet Qlik Sense die Abfrage aus dem Cache, anstatt die Quelldaten abzufragen. Wenn eine andere Auswahl getroffen wird, erfolgt eine SQL-Abfrage in der Datenquelle. Die gecachten Ergebnisse werden unter Benutzern geteilt.
Beispiel:
-
Der Benutzer wendet die ursprüngliche Auswahl an.
SQL wird an die zugrunde liegende Datenquelle weitergegeben.
-
Der Benutzer löscht die Auswahl und wendet die gleiche Auswahl wie die ursprüngliche an.
Das Cache-Ergebnis wird ausgegeben, SQL wird nicht an die zugrunde liegende Datenquelle weitergegeben.
-
Der Benutzer wendet eine andere Auswahl an.
SQL wird an die zugrunde liegende Datenquelle weitergegeben.
Beim Caching kann mit der Systemvariablen DirectCacheSeconds ein Zeitlimit festgelegt werden. Sobald das Zeitlimit erreicht ist, löscht Qlik Sense den Cache für die Direct Discovery-Abfrageergebnisse, die für die zuvor ausgewählten Optionen generiert wurden. Qlik Sense fragt dann die Quelldaten nach den ausgewählten Optionen ab und erstellt den Cache für das festgelegte Zeitlimit neu.
Die Standard-Cachezeit für Direct Discovery-Abfrageergebnisse ist 30 Minuten, sofern die DirectCacheSeconds-Systemvariable verwendet wird.