
In-memory model
In the Qlik Sense in-memory model, all unique values in the fields selected from a table in the load script are loaded into field structures, and the associative data is simultaneously loaded into the table. The field data and the associative data is all held in memory.
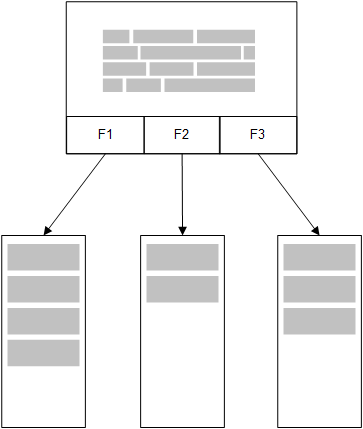
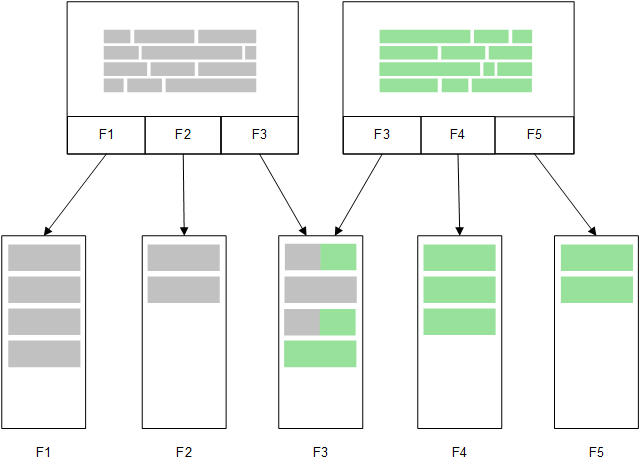
A second, related table loaded into memory would share a common field, and that table might add new unique values to the common field, or it might share existing values.
Direct Discovery
When table fields are loaded with a Direct Discovery LOAD statement (Direct Query), a similar table is created with only the DIMENSION fields. As with the In-memory fields, the unique values for the DIMENSION fields are loaded into memory. But the associations between the fields are left in the database.
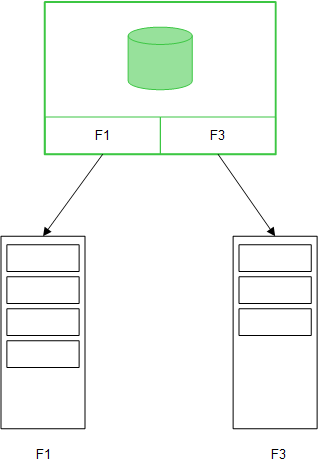
MEASURE field values are also left in the database.
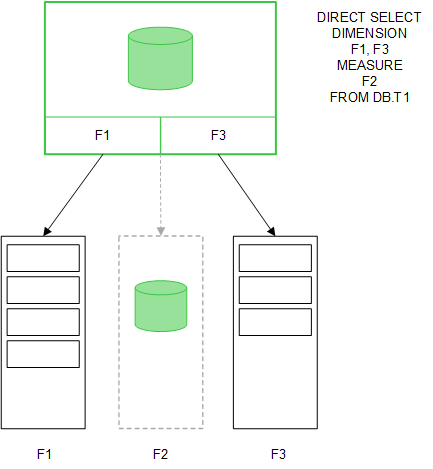
Once the Direct Discovery structure is established, the Direct Discovery fields can be used with certain visualization objects, and they can be used for associations with in-memory fields. When a Direct Discovery field is used, Qlik Sense automatically creates the appropriate SQL query to run on the external data. When selections are made, the associated data values of the Direct Discovery fields are used in the WHERE conditions of the database queries.
With each selection, the visualizations with Direct Discovery fields are recalculated, with the calculations taking place in the source database table by executing the SQL query created by Qlik Sense. The calculation condition feature can be used to specify when visualizations should be recalculated. Until the condition is met, Qlik Sense does not send queries to recalculate the visualizations.
Performance differences between in-memory fields and Direct Discovery fields
In-memory processing is always faster than processing in source databases. Performance of Direct Discovery reflects the performance of the system running the database processing the Direct Discovery queries.
It is possible to use standard database and query tuning best practices for Direct Discovery. All of the performance tuning should be done on the source database. Direct Discovery does not provide support for query performance tuning from the Qlik Sense app. It is possible, however, to make asynchronous, parallel calls to the database by using the connection pooling capability. The load script syntax to set up the pooling capability is:
SET DirectConnectionMax=10;
Qlik Sense caching also improves the overall user experience. See Caching and Direct Discovery below.
Performance of Direct Discovery with DIMENSION fields can also be improved by detaching some of the fields from associations. This is done with the DETACH keyword on DIRECT QUERY. While detached fields are not queried for associations, they are still part of the filters, speeding up selection times.
While Qlik Sense in-memory fields and Direct Discovery DIMENSION fields both hold all their data in memory, the manner in which they are loaded affects the speed of the loads into memory. Qlik Sense in-memory fields keep only one copy of a field value when there are multiple instances of the same value. However, all field data is loaded, and then the duplicate data is sorted out.
DIMENSION fields also store only one copy of a field value, but the duplicate values are sorted out in the database before they are loaded into memory. When you are dealing with large amounts of data, as you usually are when using Direct Discovery, the data is loaded much faster as a DIRECT QUERY load than it would be through the SQL SELECT load used for in-memory fields.
Differences between data in-memory and database data
DIRECT QUERY is case-sensitive when making associations with in-memory data. Direct Discovery selects data from source databases according to the case-sensitivity of the database fields queried. If the database fields are not case-sensitive, a Direct Discovery query might return data that an in-memory query would not. For example, if the following data exists in a database that is not case-sensitive, a Direct Discovery query of the value "Red" would return all four rows.
| ColumnA | ColumnB |
|---|---|
| red | one |
| Red | two |
| rED | three |
| RED | four |
An in-memory selection of "Red," on the other hand, would return only:
Red two
Qlik Sense normalizes data to an extent that produces matches on selected data that databases would not match. As a result, an in-memory query may produce more matching values than a Direct Discovery query. For example, in the following table, the values for the number "1" vary by the location of spaces around them:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
| '2' | two |
If you select "1" in a Filter pane for ColumnA, where the data is in standard Qlik Sense in-memory, the first three rows are associated:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
If the Filter pane contains Direct Discovery data, the selection of "1" might associate only "no_space". The matches returned for Direct Discovery data depend on the database. Some return only "no_space" and some, like SQL Server, return "no_space" and "space_after".
Caching and Direct Discovery
Qlik Sense caching stores selection states of queries and associated query results in memory. As the same types of selections are made, Qlik Sense leverages the query from the cache instead of querying the source data. When a different selection is made, an SQL query is made on the data source. The cached results are shared across users.
Example:
-
User applies initial selection.
SQL is passed through to the underlying data source.
-
User clears selection and applies same selection as initial selection.
Cache result is returned, SQL is not passed through to the underlying data source.
-
User applies different selection.
SQL is passed through to the underlying data source.
A time limit can be set on caching with the DirectCacheSeconds system variable. Once the time limit is reached, Qlik Sense clears the cache for the Direct Discovery query results that were generated for the previous selections. Qlik Sense then queries the source data for the selections and recreates the cache for the designated time limit.
The default cache time for Direct Discovery query results is 30 minutes unless the DirectCacheSeconds system variable is used.