
Activation du lignage de données pour les Jobs Big Data
Configurer le lignage de données avec Cloudera Navigator
Le support de Cloudera Navigator est à présent disponible dans les Jobs Spark .
Si vous utilisez une version Cloudera 5.5 ou supérieure pour exécuter vos Jobs, vous pouvez utiliser Cloudera Navigator pour visualiser le lignage d'un flux de données afin de découvrir comment ce flux de données a été généré par un Job Spark, y compris les composants utilisés dans ce Job et les modifications des schémas entre les composants.
Si vous utilisez CDP Private Cloud Base ou le Cloud Public CDP pour exécuter vos Jobs, il est recommandé d'utiliser Apache Atlas. Si vous utilisez une distribution CDP dynamique, Apache Atlas est utilisé à la place de Cloudera Navigator. Pour plus d'informations, consultez Configurer le lignage de données avec Atlas.
Par exemple, vous avez créé le Job et souhaitez générer des informations de lignage à son sujet :
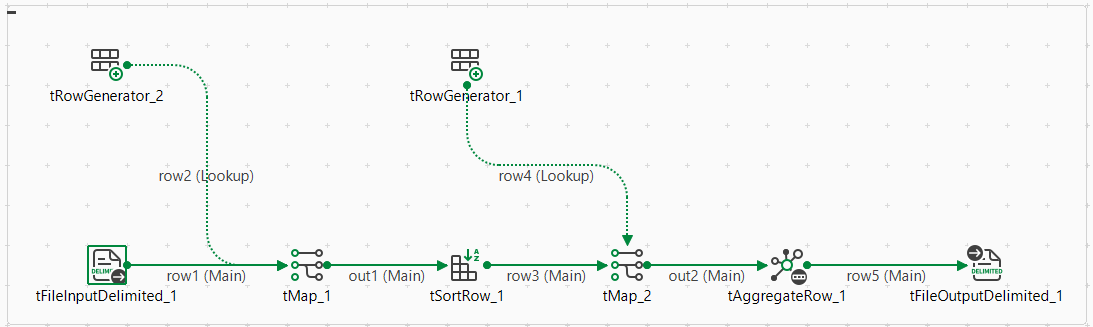
- Cliquez sur l'onglet Run (Exécuter) pour ouvrir la vue correspondante puis sur l'onglet Hadoop Configuration (Configuration de Hadoop). Pour un Job Spark, l'onglet à utiliser est Spark configuration (Configuration de Spark).
- Dans la liste Distribution, sélectionnez Cloudera et, dans la liste Version, sélectionnez Cloudera 5.5. La case Use Cloudera Navigator s'affiche.
- Kill the job if Cloudera Navigator fails : cochez cette case pour arrêter l'exécution du Job lorsque la connexion à Cloudera Navigator échoue. Sinon, laissez cette case décochée pour que votre Job continue à s'exécuter.
La connexion à Cloudera Navigator a été configurée. Lorsque vous exécutez ce Job, le lignage est automatiquement généré dans Cloudera Navigator. Vous devez configurer les autres paramètres dans l'onglet Spark configuration (Configuration de Spark) pour exécuter le Job avec succès.
Une fois l'exécution du Job terminé, effectuez une recherche dans Cloudera Navigator pour chercher les données écrites par ce Job et voir le lignage de ces données dans Cloudera Navigator. Si vous comparez le graphique de lignage au Job dans le , vous pouvez voir que chaque composant est présenté dans ce graphique.
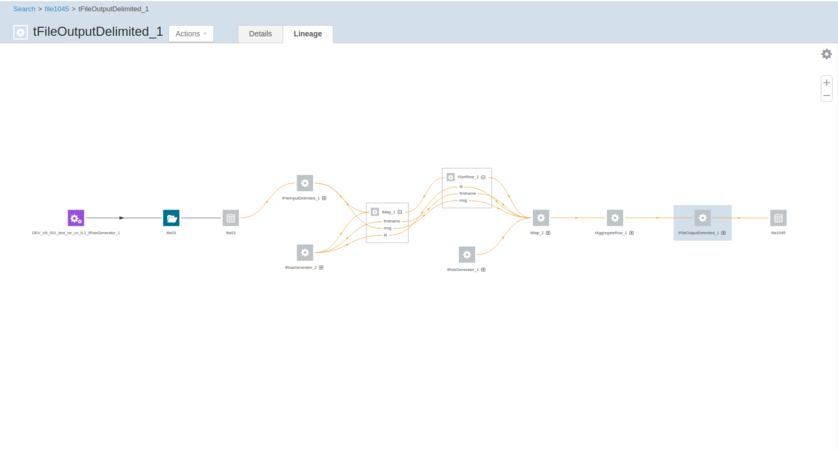
Pour plus d'informations concernant les versions de Cloudera Navigator supportées par le , consultez Versions supportées de Cloudera Navigator pour les Jobs Talend.
Configurer le lignage de données avec Atlas
Le support d'Apache Atlas est à présent disponible dans les Jobs Spark .
Si vous utilisez Hortonworks Data Platform V2.4 ou supérieure pour exécuter vos Jobs et qu'Apache Atlas est installé dans votre cluster Hortonworks, vous pouvez utiliser Atlas afin de visualiser le lignage d'un flux de données pour découvrir comment ces données ont été générées par un Job Spark, notamment dans les composants utilisés dans ce Job et voir les modifications des schémas entre les composants.
Si vous utilisez CDP Private Cloud Base ou CDP Public Cloud pour exécuter vos Jobs et qu'Apache Atlas est déjà installé sur votre cluster, vous pouvez également utiliser Atlas au lieu de Spark Universal 3.3.x (recommandé) ou de Cloudera CDP 7.x [Built-in] dans Spark Configuration (Configuration de Spark).
Par exemple, si vous avez créé le Job Spark Batch suivant et que vous souhaitez générer les informations de lignage le concernant dans Atlas :
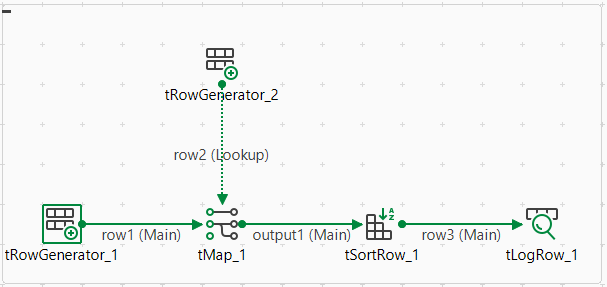
Dans ce Job, le tRowGenerator est utilisé pour générer les données d'entrée, le tMap et le tSortRow sont utilisés pour traiter les données et les autres composants pour écrire les données en sortie dans différents formats.
- Cliquez sur l'onglet Run pour ouvrir la vue correspondante puis sur l'onglet Spark Configuration.
- Dans la liste Distribution et dans la liste Version, sélectionnez votre distribution Hortonworks. La case Use Atlas (Utiliser Atlas) s'affiche.
- Die on error : cochez cette case pour arrêter l'exécution du Job lorsque des problèmes relatifs à Atlas surviennent, par exemple des problèmes de connexion à Atlas. Sinon, laissez cette case décochée pour que votre Job continue à s'exécuter.
La connexion à Atlas a été configurée. Lorsque vous exécutez ce Job, le lignage est automatiquement généré dans Atlas. Vous devez configurer les autres paramètres dans l'onglet Spark configuration (Configuration de Spark) pour exécuter le Job avec succès. Pour plus d'informations, consultez Créer un Job Spark Batch.
Lorsque l'exécution du Job est terminée, effectuez une seconde recherche dans Atlas pour trouver les informations de lignage écrites par ce Job et pour y lire le lignage.
Lire le lignage Atlas
-
-
le Job lui-même,
-
les composants dans le Job utilisant des schémas de données, comme le tRowGenerator ou le tSortRow. Les composants de connexion ou de configuration comme le tHDFSConfiguration ne sont pas pris compte étant donné que ces composants n'utilisent pas de schéma.
-
-
Talend pour toutes les entités générées par le Job,
-
TalendComponent pour toutes les entités des composants.,
-
TalendJob pour toutes les entités de Jobs.
Vous pouvez cliquer directement sur l'un de ces libellés dans Atlas pour afficher les entités correspondantes.
