
Architecture fonctionnelle de Talend Data Fabric
L'architecture fonctionnelle du Talend Data Fabric est un modèle architectural qui identifie les fonctions, les interactions et les besoins informatiques correspondants du Talend Data Fabric. L'architecture d'ensemble a été décrite en isolant les fonctionnalités spécifiques en blocs fonctionnels.
Le diagramme suivant illustre les blocs fonctionnels de l'architecture principale.
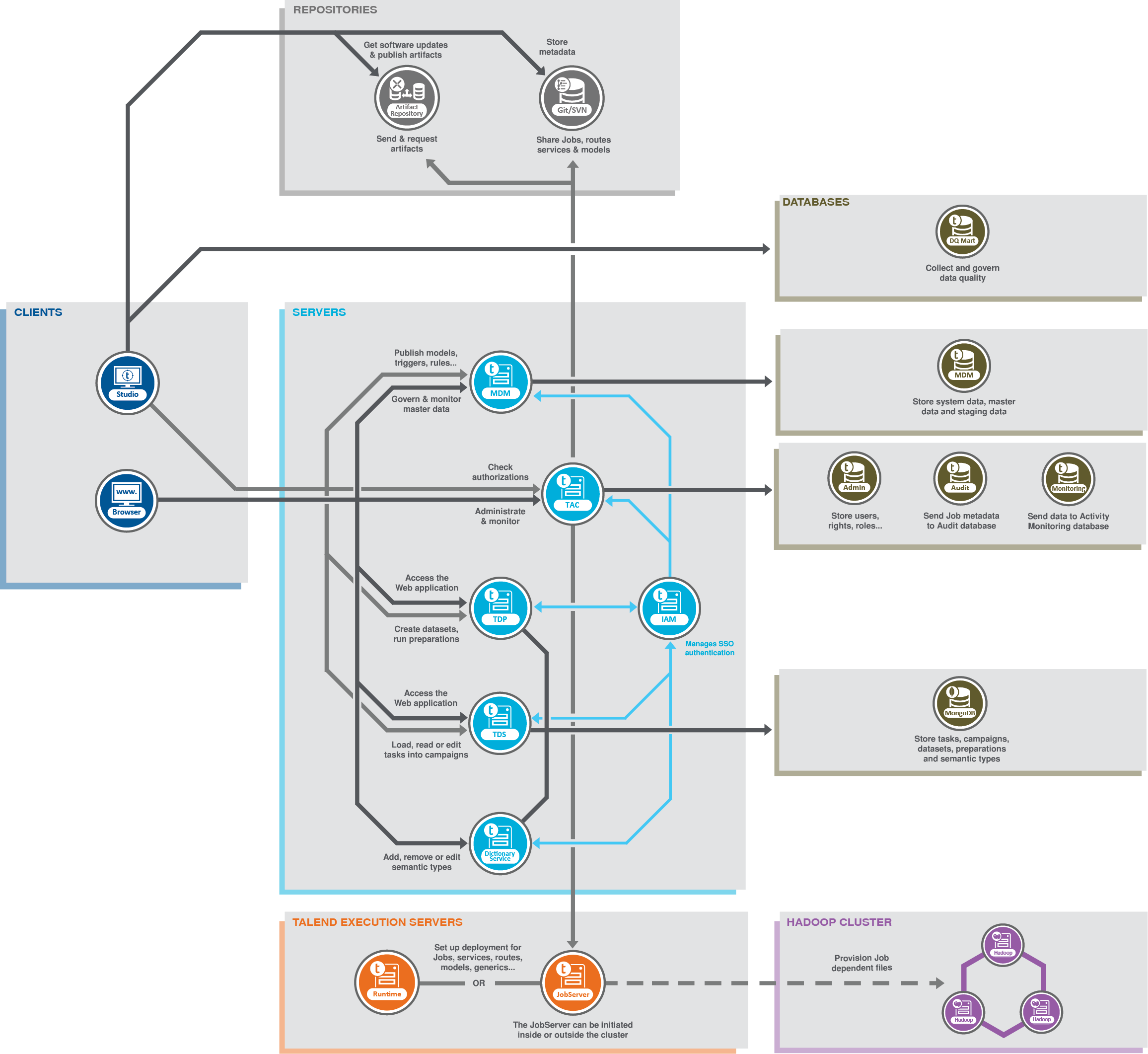
Plusieurs de ces blocs fonctionnels sont définis :
- Dans le Studio Talend, vous créez et exécutez des Jobs Big Data tirant parti du cluster Hadoop afin de gérer de grands volumes de données. Une fois lancés, ces Jobs sont envoyés, déployés et exécutés sur ce cluster Hadoop.
Dans le Studio, vous pouvez aussi utiliser des modèles et indicateurs prédéfinis pour analyser des données stockées dans différentes sources de données, parcourir les résultats de requêtes et les interroger, supprimer les données corrompues, incomplètes ou imprécises.
- Un cluster Hadoop indépendant du système Talend pour gérer d'importants ensembles de données.
- Un JobServer ou Runtime Talend installé dans le cluster Hadoop ou hors du cluster Hadoop, pour déployer et exécuter les Jobs.
Pour un cluster Hortonworks, il est recommandé d'installer le JobServer ou le Runtime dans le nœud EDGE de la machine afin d'éviter des problèmes potentiels de pare-feu ou d'accès.
Pour un cluster Amazon EMR, il est également recommandé d'installer le JobServer ou le Runtime dans le cluster.
- À partir de Talend DQ Portal, vous pouvez générer des rapports sur les résultats d'analyse et les partager avec d'autres utilisateur·trices métier.