
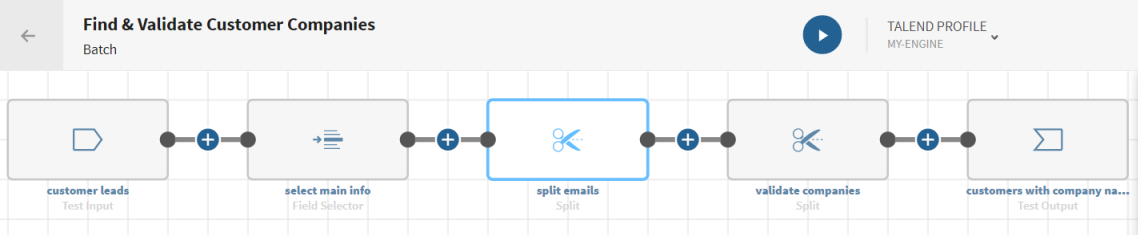
Trouver des entreprises clientes en se basant sur des prospects
Avant de commencer
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Téléchargez et extrayez le fichier split-leads.zip. Il contient un jeu de données comprenant la liste des prospects, ainsi que leur prénom, nom, adresse e-mail ou adresse.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un fichier stocké dans une connexion de test.
Procédure
-
Cliquez sur le bouton
 et ajoutez un processeur Field selector au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Field selector au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
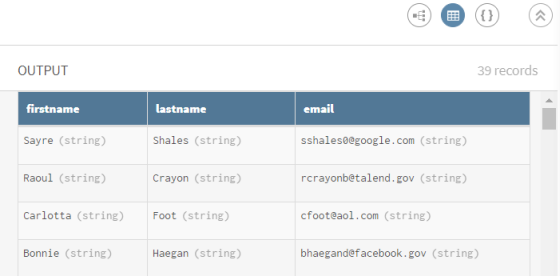
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération de restructuration.
-
Cliquez sur le bouton et ajoutez un processeur Split au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur le bouton et ajoutez un processeur Split au pipeline. Le panneau de configuration s'ouvre.
-
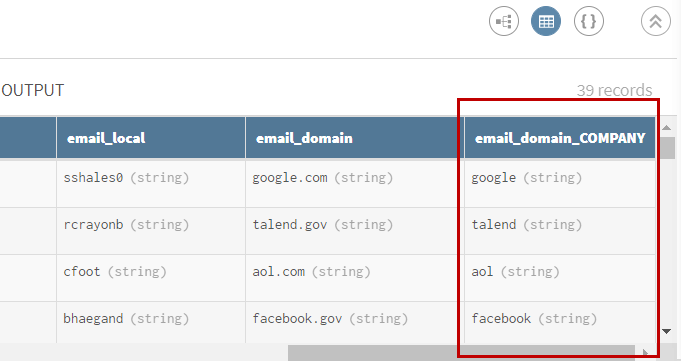
(Facultatif) Consultez l'aperçu du processeur Split pour voir les données après l'opération d'extraction.
Exemple
Résultats
Votre pipeline est en cours d'exécution, les données des prospects ont été traitées, les entreprises clientes ont été validées par rapport aux types sémantiques des entreprises et le flux de sortie est envoyé au système cible indiqué.