
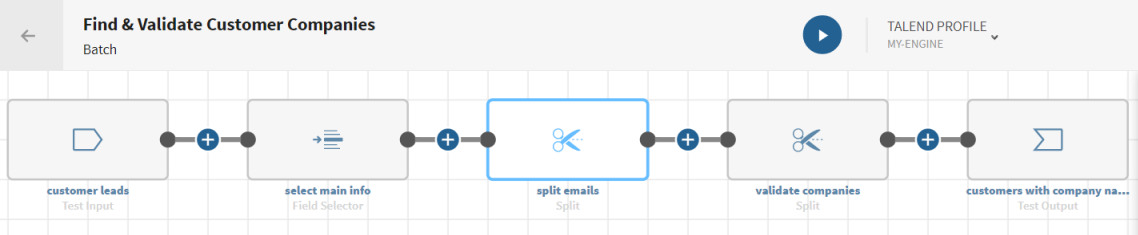
Finding customer companies based on leads
Before you begin
-
You have previously added the dataset holding your source data.
Download and extract the file: split-leads.zip. It contains a dataset with a list of customer leads including first names, last names, emails, addresses, etc.
-
You also have created the connection and the related dataset that will hold the processed data.
Here, a file stored in a Test Connection.
Procedure
-
Click
 and add a Field Selector processor to the pipeline.
The configuration panel opens.
and add a Field Selector processor to the pipeline.
The configuration panel opens.
-
Click Save to
save your configuration.
(Optional) Look at the preview of the processor to compare your data before and after the restructuring operation.

-
Click and add a Split processor to the pipeline. The
configuration panel opens.
-
Click and add another Split processor to the pipeline. The
configuration panel opens.
-
(Optional) Look at the preview of the Split processor to see your data after the
extract operation.
Example

Results
Your pipeline is being executed, the leads data has been processed, customer companies have been validated against company semantic types and the output flow is sent to the target system you have indicated.