
Extraire un échantillon de taille fixe d'un jeu de données concernant des conducteur·trices
Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source.
Ici, une connexion de test.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
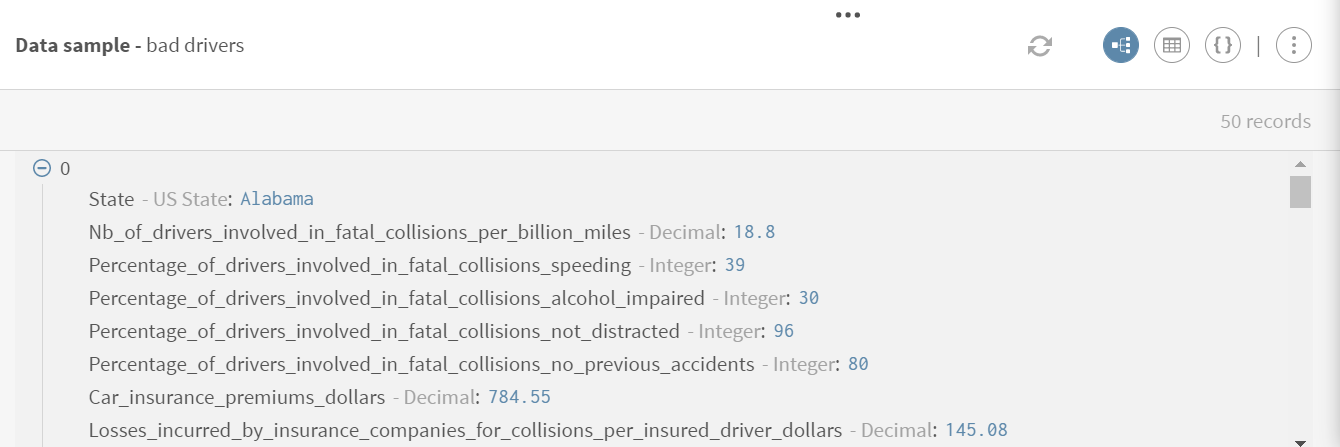
Téléchargez et extrayez le fichier sampling-drivers.zip. Il contient un jeu de données concernant des mauvais·es conducteur·trices, notamment le pourcentage de conducteur·trices impliqué·es dans des collisions mortelles liées à la vitesse, l'alcool, une distraction, ou encore des informations concernant les assurances des voitures.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un dossier de sortie stocké sur un serveur FTP.
Procédure
-
Cliquez sur ADD SOURCE pour ouvrir le panneau vous permettant de sélectionner vos données source, ici les données relatives aux collisions mortelles et aux assurances.
Exemple
-
Cliquez sur le bouton
 et ajoutez un processeur Data sampling au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Data sampling au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
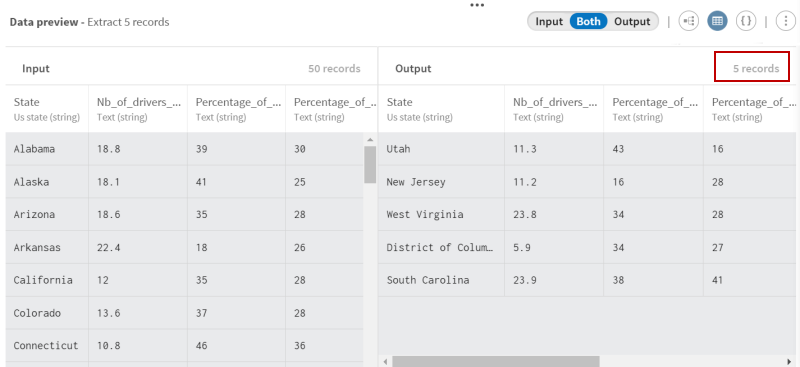
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération.
Vous pouvez constater qu'un sous-jeu de données contenant 5 enregistrements sélectionnés aléatoirement a été créé dans la sortie.
Résultats
Votre pipeline est en cours d’exécution, le sous-jeu de données est créé selon le nombre d'enregistrements spécifié et la sortie est envoyée vers le dossier FTP défini. Ces sous-jeux de données peuvent être utilisés par des data scientists pour des analyses de prédictions.