
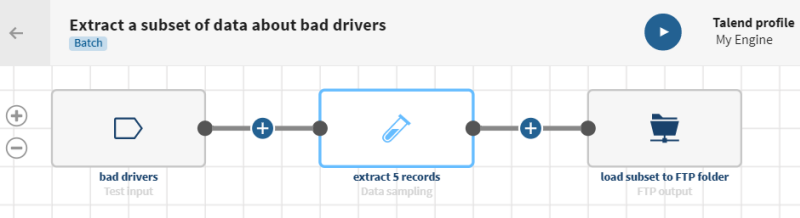
Extracting a fixed-size sample from a dataset about drivers
Before you begin
-
You have previously created a connection to the system storing your source data.
Here, a Test connection.
-
You have previously added the dataset holding your source data.
Download and extract the file: sampling-drivers.zip. It contains a dataset with data about bad drivers, including the percentage of drivers involved in fatal collisions due to speed, alcohol, distractions, information about car insurances, etc.
-
You also have created the connection and the related dataset that will hold the processed data.
Here, an output folder stored on an FTP server.
Procedure
-
Click ADD SOURCE to open
the panel allowing you to select your source data, here data about drivers
involved in fatal collisions and insurance data.
Example

-
Click
 and add a Data sampling processor to the pipeline.
The configuration panel opens.
and add a Data sampling processor to the pipeline.
The configuration panel opens.
-
Click Save to
save your configuration.
Look at the preview of the processor to compare your data before and after the operation.
You can see that a subset that contains only 5 records selected randomly has been created in the output.

Results
Your pipeline is being executed, the subset of data is created according to the number of records you have specified and the output is sent to the FTP folder you have indicated. These subsets of data can then be used by data scientists for predictive analytics.