Filtrer les tâches à l'aide des modèles
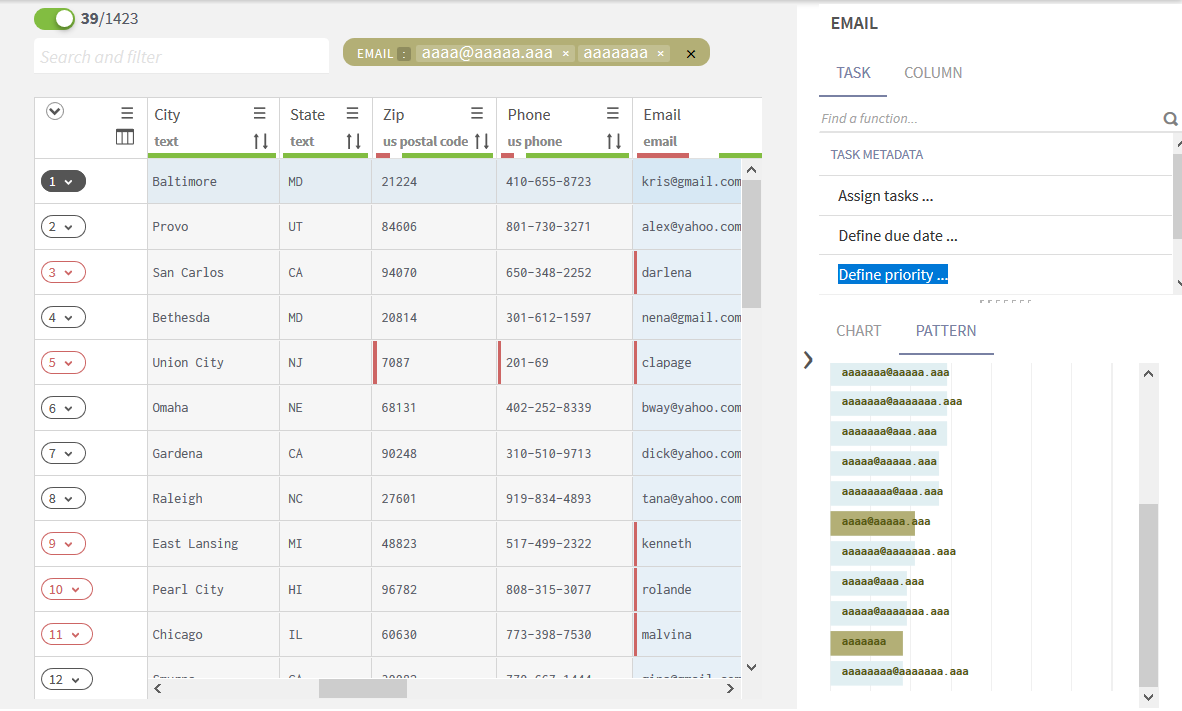
L'onglet Pattern (Modèles) de la zone de profiling de données affiche une représentation graphique du type et du nombre de caractères qui constituent vos données. En d'autres termes, vous pourrez voir comment sont structurés les enregistrements, avec une granularité de mot ou de caractère.
Il peut également être utilisé pour filtrer rapidement et simplement vos données.
Lorsque vous sélectionnez le contenu d'une colonne, un diagramme à barres horizontales affiche la répartition des différents modèles, représentant ainsi le type et le nombre de caractères ou mots composant les données.
Vous pouvez passer d'un modèle basé sur des caractères à un modèle basé sur les mots depuis l'onglet Pattern, sauf pour les données numériques, pour lesquelles seuls les modèles basés sur des caractères sont calculés.
Analyser des modèles basés sur les mots est un moyen efficace de détecter des problèmes de qualité de données dans les prénoms ou les noms de famille, par exemple. Les noms qui ne sont pas uniquement composés de mots, par exemple avec des signes de ponctuation ou des chiffres se démarquent au premier coup d’œil. Les modèles basés sur des caractères conviennent mieux aux données structurées, comme les ID clients ou les numéros de comptes. À partir du tableau, vous pouvez savoir si le nombre de caractères ou chiffres est incorrect.
Procédure
-
Sélectionnez PATTERN dans le panneau de droite.
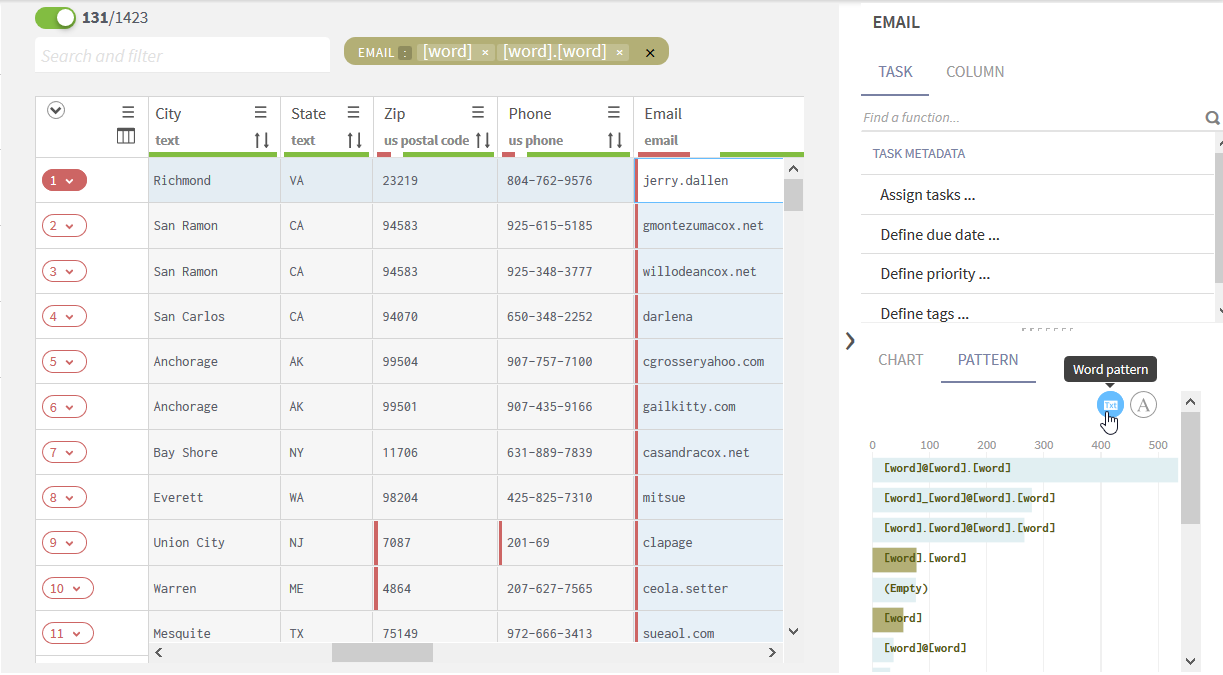
Tous les modèles basés sur des mots représentant les valeurs de la colonne EMAIL sont calculés et affichés.
-
Pour passer aux modèles basés sur des caractères pour les adresses e-mail, cliquez sur l'icône A dans le coin supérieur droit de la vue PATTERN.