Configurer les composants
Procédure
-
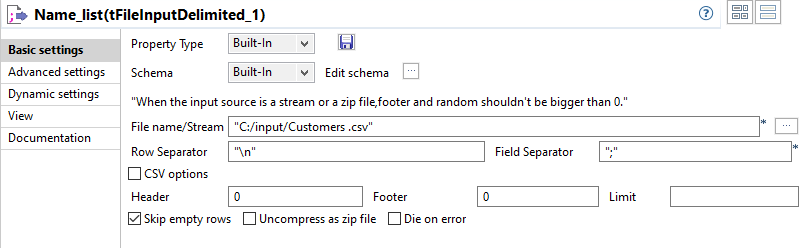
Double-cliquez sur le composant tFileInputDelimited afin d'afficher sa vue Basic settings.
-
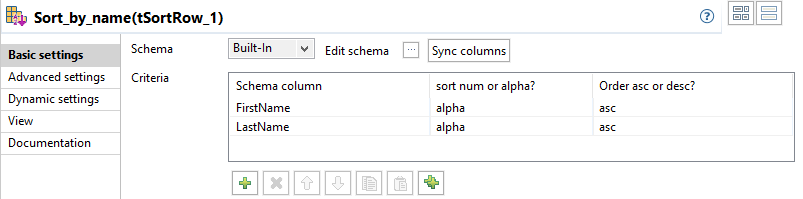
Double-cliquez sur le tSortRow afin d'afficher sa vue Basic settings.
-
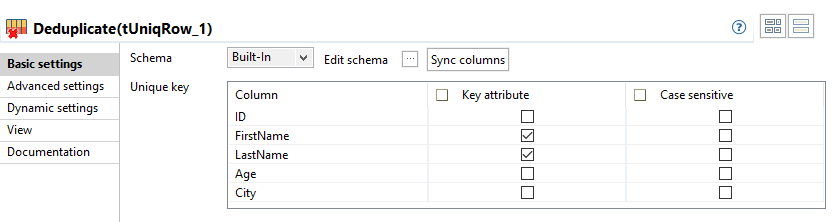
Double-cliquez sur le composant tUniqRow afin d'afficher sa vue Basic settings.