
Assistant de configuration
L'assistant de configuration vous permet de créer différents environnements de production, Configurations et leurs règles de rapprochement.
Vous pouvez également utiliser l'assistant de configuration pour importer les règles de mise en correspondance créées et testées dans le Studio Talend afin de les utiliser dans vos Jobs de mise en correspondance. Pour plus d'informations, consultez Import de règles de rapprochement depuis le référentiel.
Vous ne pouvez pas ouvrir l'assistant de configuration sans avoir lié le composant d'entrée au tMatchGroup.
Ouvrir l'assistant de configuration
Procedure
-
Dans l'espace de modélisation du Studio Talend, concevez votre Job et reliez les composants, comme montré ci-dessous.

-
Pour configurer le tMatchGroup, choisissez l'une des méthodes suivantes :
- Double-cliquez sur le tMatchGroup ; ou cliquez-droit dessus et sélectionnez Configuration Wizard dans le menu contextuel.
- Dans la vue Basic settings du tMatchGroup, cliquez sur Preview.

Results
-
La vue Configuration, dans laquelle vous pouvez configurer les règles de rapprochement et la·es colonne·s de bloc.
-
La table des correspondances, qui affiche les résultats graphiques du rapprochement.
-
la table des correspondances, qui affiche les résultats détaillés du rapprochement.
Le champ Limit dans le coin supérieur gauche indique le nombre maximal de lignes à traiter par la règle de rapprochement, dans l’assistant. Par défaut, le nombre maximum de lignes est 1000.
La vue Configuration
Dans cette vue, vous pouvez modifier la configuration du tMatchGroup ou définir différentes configurations dans lesquelles exécuter le Job.
About this task
Vous pouvez, par exemple, utiliser ces différentes configurations pour effectuer des tests. Cependant, vous ne pouvez enregistrer qu'une configuration à partir de cet assistant, à savoir la configuration courante.
Dans chaque configuration, vous pouvez définir les paramètres de génération des règles de rapprochement avec les algorithmes VSR ou T-Swoosh. Les paramètres dans la vue Configuration sont légèrement différents si vous sélectionnez Simple VSR ou T-Swoosh dans l'onglet Basic settings du tMatchGroup.
Vous pouvez définir des règles de consolidation, une ou plusieurs clés de bloc et plusieurs conditions utilisant différentes règles de rapprochement. Vous pouvez également définir différents intervalles de correspondance pour chaque règle. Les résultats du rapprochement de plusieurs conditions listent les enregistrements de données qui répondent à au moins une des règles définies. Lorsqu'une configuration a plusieurs conditions, le Job effectue une opération de rapprochement de type OR. Il évalue les enregistrements de données par rapport à la première règle et les enregistrements qui correspondent à celle-ci ne sont pas évalués par rapport aux autres règles.
-
les paramètres Key definition.
-
le champ Match Threshold.
-
une clé de bloc dans la table Blocking Selection (disponible uniquement pour les règles utilisant l'algorithme VSR).
Définir une clé de bloc n'est pas obligatoire mais recommandé, car cela permet de partitionner les données en blocs afin de réduire le nombre d'enregistrements à examiner. Pour plus d'informations concernant la clé de bloc, consultez Import de règles de mise en correspondance depuis le référentiel.
-
les paramètres Survivorship Rules for Columns (disponibles uniquement pour les règles utilisant l'algorithme T-Swoosh).
-
les paramètres Default Survivorship Rules pour les types de données (disponibles uniquement pour les règles utilisant l'algorithme T-Swoosh).
Procedure
-
Cliquez sur le bouton [+] dans le coin supérieur droit de la vue Configuration.
Cela crée, dans un nouvel onglet, une copie identique de la dernière configuration.
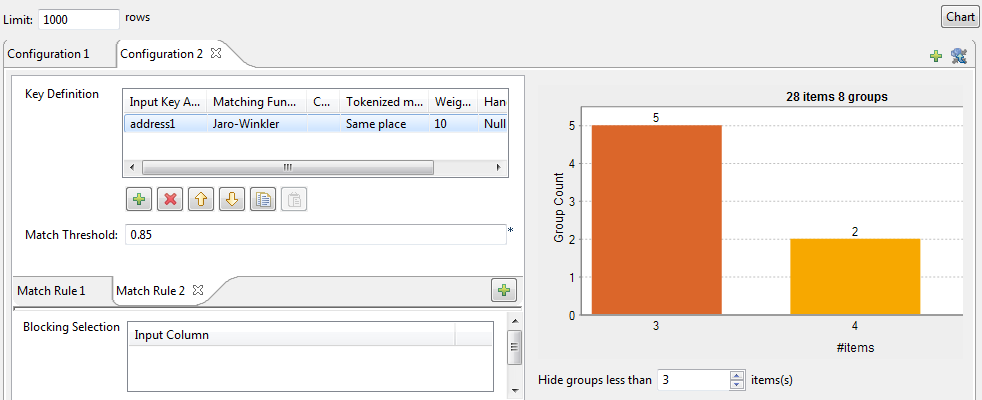
Le graphique des correspondances
About this task
Le paramètre Hide groups less than, configuré à 2 par défaut, vous permet de sélectionner les groupes que vous souhaitez afficher dans le graphique. On souhaite généralement masquer les groupes de petite taille.
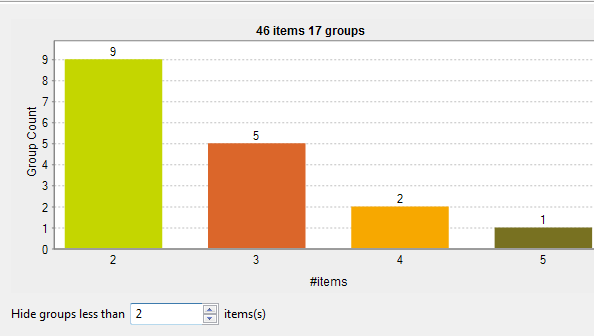
-
46 éléments sont analysés et divisés en 17 groupes selon une règle de rapprochement donnée et après avoir exclu les éléments uniques. Le paramètre Hide groups less than avec la valeur 2 a été utilisé pour exclure les groupes inférieurs à deux.
-
Neuf groupes ont deux éléments chacun. Dans chaque groupe, les deux éléments sont des doublons l'un de l'autre.
-
cinq groupes ont trois éléments chacun. Dans chaque groupe, ces éléments sont des doublons d'un autre.
-
deux groupes ont quatre éléments chacun. Dans chaque groupe, ces éléments sont des doublons d'un autre.
-
Un seul groupe a cinq éléments en doublon.
La table des correspondances
About this task
Cette table affiche le détail des correspondances des éléments de chaque groupe et les colore selon leur couleur dans le graphique.

Vous pouvez décider des groupes à afficher dans cette table en configurant le paramètre Hide groups less than. Ce paramètre vous permet de masquer des groupes de petite taille. Il est configuré sur 2 par défaut.
Les boutons sous la table vous permettent de naviguer entre les différentes pages.