Traiter en masse des tables Lookup volumineuses
Cet article présente comment utiliser le traitement par lots pour gérer des tables Lookup volumineuses.
Une manière de traiter ce problème est d'utiliser un processus nommé Batching (traitement par lots). Le traitement par lots permet de traiter un lot d'enregistrements en une exécution, de manière itérative afin de créer plus de lots et de traiter tous les enregistrements.
Chaque itération va traiter et extraire un nombre fixe d'enregistrements depuis les tables source et Lookup, effectuer une jointure et charger la table cible.
Ainsi, vous pouvez contrôler le nombre d'enregistrements (variable batchrec) en mémoire dans le traitement.
Pour ce faire, vous pouvez utiliser les variables de contexte (Context variables), le tLoop, le tContextLoad, le tMap et le tJava.
Procédure
-
Utilisez les variables de contexte pour rendre le Job dynamique. Différentes valeurs peuvent être utilisée pour les variables de contexte dans différents environnements, comme DEV et PROD. Cela rend le Job flexible et évite de modifier le code dans chaque environnement.
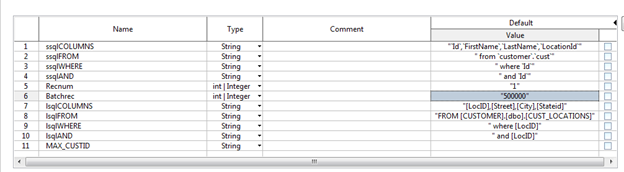
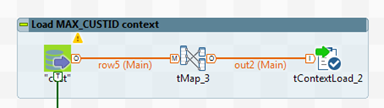
Variable Description Recnum Cette variable est utilisée comme point de départ de l'exécution. Sa valeur par défaut dans ce Job est "1" . Batchrec Cette variable est utilisée comme le nombre d'enregistrements à traiter dans le Job à chaque itération. En rendant cette variable dynamique, vous pouvez contrôler le nombre d'enregistrements à traiter dans chaque lot. MAX_CUSTID Cette variable est utilisée pour arrêter le processus après la dernière itération, c'est-à-dire après la lecture du dernier enregistrement. Cette variable est chargée à l'aide du composant tContextLoad. La requête SQL est la suivante : "SELECT 'MAX_CUSTID' as Key, max(id) as Value FROM `customer`.`cust` "
-
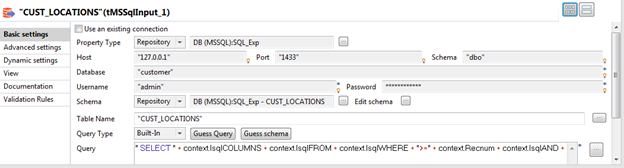
Utilisez les variables sssql et lsql pour construire l'isntruction SQL à exécuter sur la base de données par les composants tMysqlInput et tMSSqlInput. Les colonnes choisies dans ssqlCOLUMNS et lsqlCOLUMNS doivent être les mêmes que celles du schéma défini dans les composants d'entrée.
Par exemple, la requête dans le composant client (tMysqlInput) est définie comme suit, rendant la requête dynamique.
" SELECT " + context.ssqlCOLUMNS + context.ssqlFROM + context.ssqlWHERE + ">=" + context.Recnum + context.ssqlAND + "<" + (context.Recnum + context.Batchrec) ;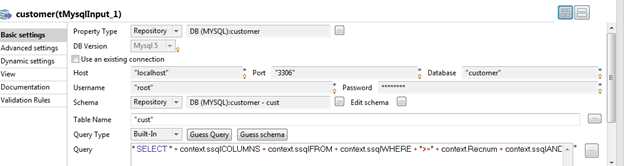
Une requête SQL similaire est définie sur le composant CUST_LOCATIONS (tMSSqlInput).
-
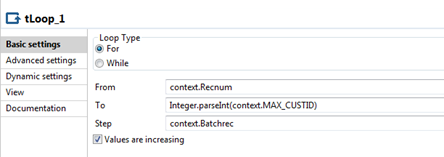
Configurez le composant tLoop comme suit.
Les variables de contexte définies ci-dessus sont utilisées dans le composant tLoop, comme présenté ci-dessous. Pour chaque itération jusqu'à l'ID client maximal, le nombre d'enregistrements par lot défini dans la variable Batchrec est utilisé pour récupérer les enregistrements depuis les tables source et Lookup.
-
Configurez le composant tJava comme suit.
Ce composant est utilisé pour incrémenter l'ID client (cust_id) de départ du nombre d'enregistrements en cours de traitement dans chaque lot.

-
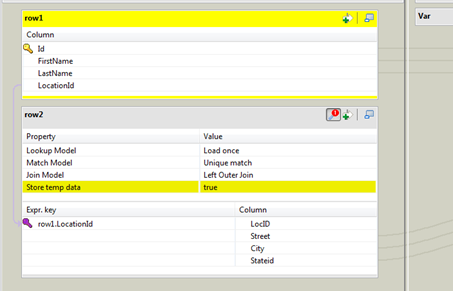
Configurez le composant tMap comme suit.
Ce composant est utilisé pour la condition de jointure Le Lookup Model est configuré à Load Once, car votre table Lookup est statique. Match Model est configuré à Unique match car vous n'attendez pas que la table Lookup ait des doublons. Join Model est configuré à Left Outer Join car vous souhaitez que les données source soient chargées dans la cible même si l'emplacement est introuvable.
-
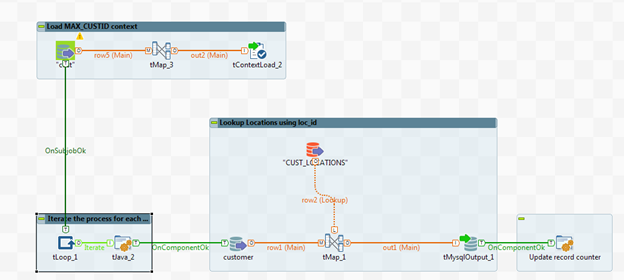
Reliez les sous-Jobs à l'aide de liens de déclenchement OnSubJobOk et OnComponentOk.
Ne reliez pas le composant tLoop directement au tMysqlInput. Ne reliez pas le tJava (Update record counter) directement au tMysqlOutput_1. Les composants tLoop et tJava doivent faire partie de leur propre sous-Jobs.
Le Job complet doit ressembler à ceci.
Résultats
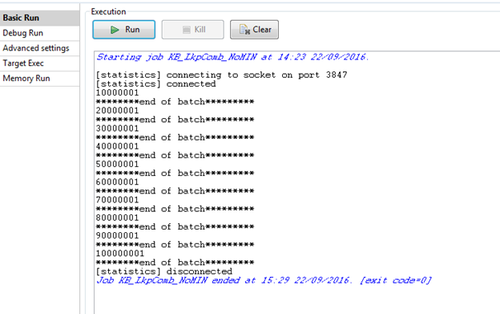
Voici le log d'exécution d'exemple. La table source (cust) contient 100 millions de lignes et la table Lookup (CUST_LOCATIONS) contient 70 millions de lignes. Batchrec="10000000".
L'exécution du Job a pris 66 minutes et a utilisé une partie de la mémoire disponible sur le serveur d'exécution. Il n'a pas été affecté par des exceptions relatives à un dépassement de mémoire.