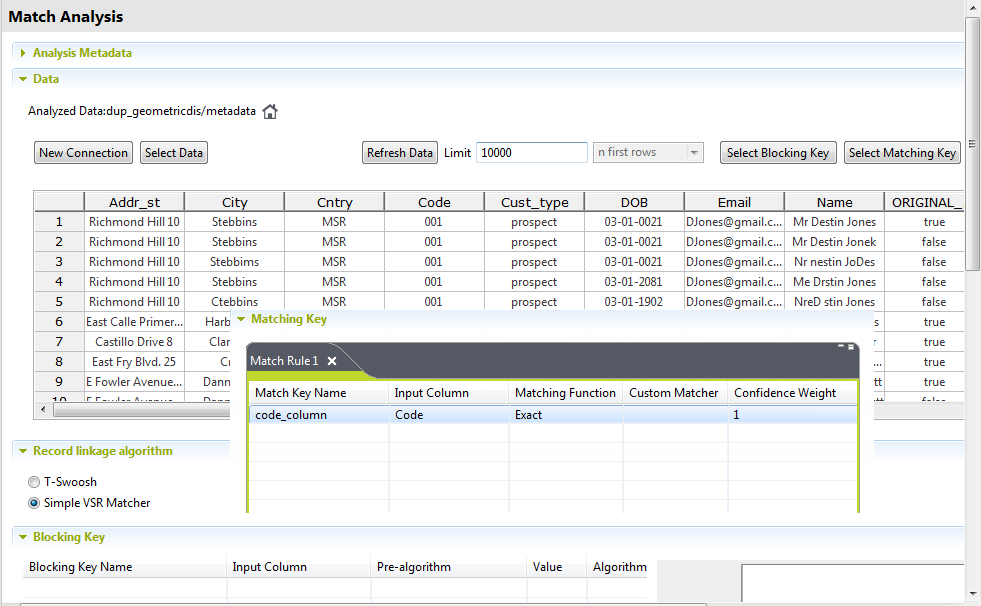
Define the match analysis
Procedure
-
In the Matching Key table, define a match key
on the Code column to group records by their
identification, records which have the same code are grouped together.