Executing the Job
Procedure
-
Right-click the output component and select Data
Viewer to display the duplicate data.
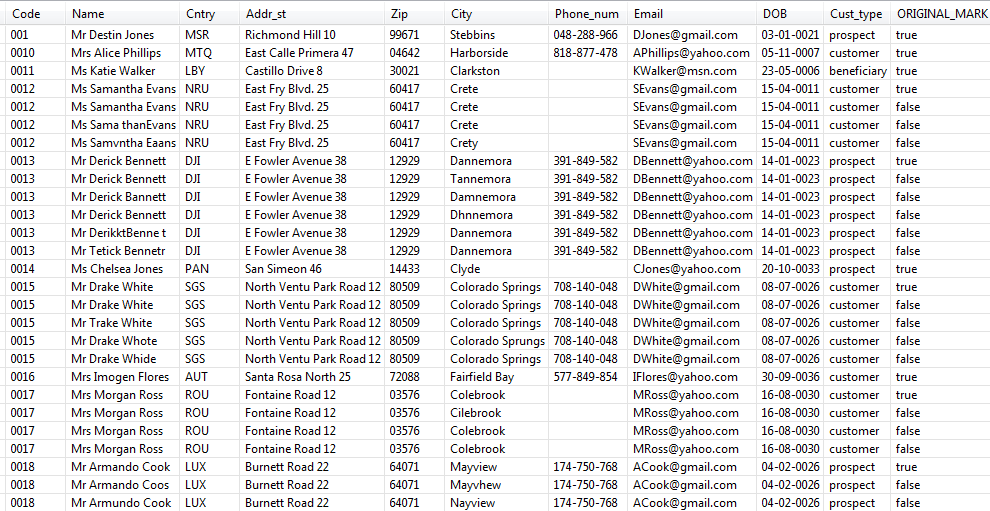
Duplicate records have been marked as false in the ORIGINAL_MARK column.
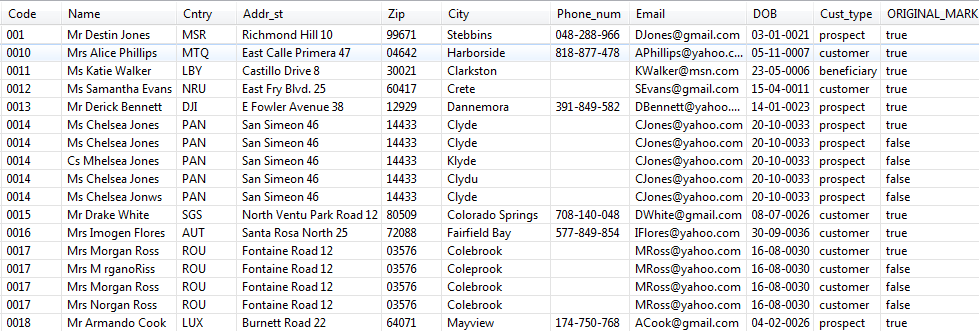 Some data has been modified in the Name, City and DOB fields according to the criteria you set in the Modifications table and duplicate records have been generated based on these modifications.For example, if you compare the original name Mrs Morgan Ross and the duplicate name Mrs M rganosRiss, you will see that the two functions have been used on this duplicate record: the letter o has been exchanged with a space, and also the sound has been replaced in Ross and Riss. However, the soundex code has not been changed for the replaced sound.
Some data has been modified in the Name, City and DOB fields according to the criteria you set in the Modifications table and duplicate records have been generated based on these modifications.For example, if you compare the original name Mrs Morgan Ross and the duplicate name Mrs M rganosRiss, you will see that the two functions have been used on this duplicate record: the letter o has been exchanged with a space, and also the sound has been replaced in Ross and Riss. However, the soundex code has not been changed for the replaced sound. -
In the tDuplicateRow basic settings and in
the Distribution of duplicates area, select a
different distribution, Bernoulli distribution for example,
and run the Job.
Different duplicates are generated from the same input flow according to the selected distribution as shown in the below figure.