Qlik Cloud 시작
Qlik Cloud는 Data Integration 및 분석을 위한 유일한 종단 간 솔루션이 제공하는 활성 인텔리전스를 통해 데이터, 통찰력 및 작업 간의 격차를 좁힙니다.
Qlik Cloud 소개
Qlik Cloud는 Active Intelligence를 위해 구축된 데이터 통합 및 분석 클라우드 플랫폼입니다. 함께 사용하거나 독립적으로 사용할 수 있는 데이터 통합 및 분석 서비스를 제공합니다.

시작하기 및 학습 옵션
Qlik 기술 문서에는 여정의 모든 단계에 대한 모든 기술 수준의 예, 자습서 및 문제 해결이 포함되어 있습니다.

인터페이스 개요
처음으로 Qlik Cloud에 로그인한 경우, 시작하는 데 도움이 되는 자습서와 데모를 찾을 수 있습니다.

Qlik Cloud 정부
Qlik Cloud 정부는 Qlik의 상용 Qlik Cloud 제품과 다릅니다. 여기에는 미국 공공 부문을 지원하는 데 필요한 보안 프로토콜이 포함되어 있으며 FedRAMP 중간 영향 수준(IL) 및 국방부(DOD) IL2에서 권한 부여되었습니다.
데이터 분석
Qlik Cloud Analytics는 셀프서비스 분석에서 대화형 대시보드 및 응용 프로그램, 대화형 분석, 메타데이터 카탈로그 및 계보, 모바일 분석, 보고 및 알림에 이르기까지 모든 범위의 사용자 및 사용 사례에서 최신 분석 기능을 제공합니다.

분석을 사용하여 데이터 탐색
앱 및 시각화 작업을 통해 데이터 개요를 얻을 수 있습니다. 데이터에 있는 관계를 파악함으로써 현명한 판단과 발견을 할 수 있습니다.

분석 만들기 및 데이터 시각화
강력한 분석 및 데이터 시각화를 만듭니다. 빌드하는 앱은 앱 사용자가 데이터를 시각화하고 발견할 수 있는 기반을 설정합니다.

분석 데이터 로드 및 모델링
먼저 데이터 소스를 추가하고, 데이터를 앱에 로드하고, 데이터 모델 모델링을 시작합니다.

분석을 위한 데이터 및 계보 제공
Qlik Cloud 테넌트에 계보 및 온프레미스 데이터를 로드하는 옵션.

Qlik 프로젝트을 사용한 기계 학습
자동화된 기계 학습은 데이터에서 패턴을 찾고 이를 사용하여 미래 데이터를 예측합니다.
데이터 통합
Qlik Talend Cloud는 Qlik Talend Data Integration을 통해 실시간 데이터 이동, 변환 및 데이터 제품을 제공합니다. 또한 Qlik Talend Cloud에는 데이터 관리, 데이터 품질, 앱 통합을 위한 Talend 기능 등 다양한 기능이 포함되어 있습니다.

데이터 통합 소개
데이터 아키텍처 및 분석 요구 사항을 지원하기 위해 다양한 데이터 통합 작업을 수행하는 데이터 파이프라인을 만듭니다. 데이터 제품을 사용하여 데이터 관리를 간소화할 수도 있습니다.

는 무엇입니까?Qlik Talend Cloud
Talend의 더 많은 데이터 통합 기능은 Qlik Talend Cloud의 상위 계층에 포함되어 있습니다. 여기에는 향상된 데이터 관리, 데이터 품질, 앱 통합 등 다양한 기능이 포함됩니다.

데이터 통합 비디오
데이터 통합을 시작하려면 짧은 비디오를 시청하십시오.
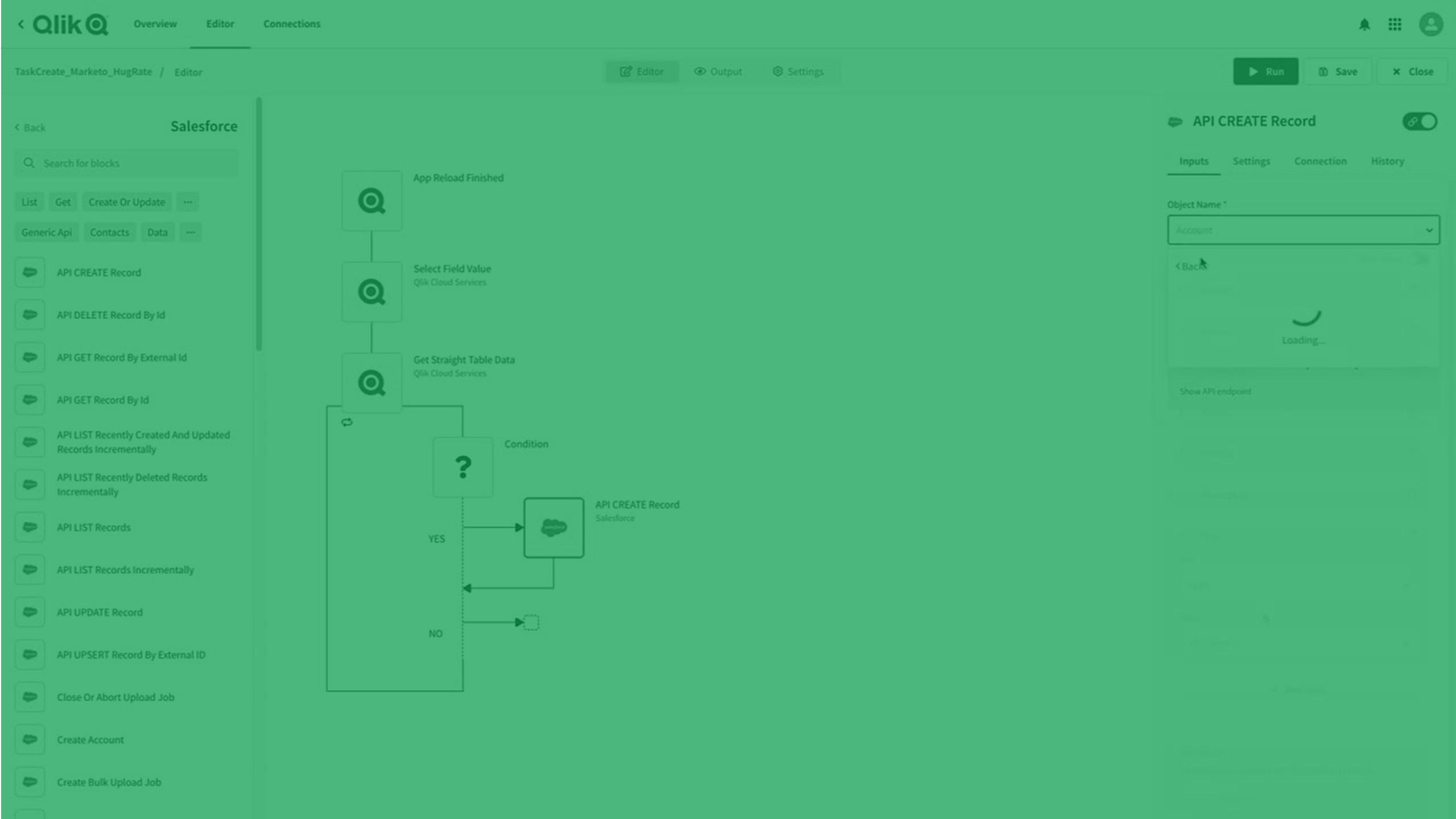
자동화 구축
Qlik Automate는 자동화된 분석 및 데이터 워크플로를 쉽게 구축할 수 있도록 하는 코드 없는 시각적 인터페이스를 제공합니다.
자동화는 프로그램처럼 실행되는 일련의 작업 및 트리거입니다. 이는 한 응용 프로그램에서 정보를 수집하여 다른 응용 프로그램으로 전달하는 간단한 워크플로우일 수도 있고, 원시 데이터에서 Active Intelligence로 이동하는 엔드투엔드 파이프라인일 수도 있습니다. Qlik Automate을 사용하면 분석 환경을 자동화하고, 데이터 기반 워크플로를 만들고, 데이터와 분석을 비즈니스 프로세스에 포함할 수 있습니다.
관리
관리자는 Qlik Cloud 구독 및 환경을 배포, 구성 및 관리할 책임이 있습니다. Qlik Cloud 환경은 중앙 집중식 관리 및 거버넌스를 제공하고 사용자 채택, 정확성 및 시스템 안정성을 보장하는 데 도움이 됩니다.

Qlik Cloud 배포 계획
Qlik Cloud 배포를 성공적으로 계획하려면 회사의 지리적 분포, 기존 배포, 보안, 용량, Qlik Sense 구독 및 환경 관리 방법과 같은 요소를 고려해야 합니다.

Qlik Cloud 배포
Qlik Cloud를 배포하려면 등록, 시스템 구성, 사용자 추가 및 관리 프로세스 설정을 포함하는 높은 수준의 표준 단계를 따르십시오.

관리Qlik Cloud
Qlik Cloud 환경은 중앙 집중식 관리 및 거버넌스를 제공하고 사용자 채택, 정확성 및 시스템 안정성을 보장하는 데 도움이 됩니다. 테넌트 관리에는 사용자 및 리소스 관리, 보안 설정 및 일반 시스템 관리가 포함됩니다.
분석 및 데이터 통합 개발
Qlik Cloud API 및 도구를 사용하여 사용자 지정 데이터 기반 응용 프로그램을 구축, 확장 및 배포합니다. 또한 매시업을 구축하거나, 앱과 시각화를 즉시 만들거나, 풍부하고 몰입하도록 하는 분석을 애플리케이션에 포함할 수 있습니다.
로 마이그레이션Qlik Cloud
마이그레이션 센터에서 사용자와 관리자가 Qlik Cloud에 대한 최신 정보를 빠르게 가져올 수 있습니다. QlikView 또는 Qlik Sense Enterprise Client-Managed에서 Qlik Cloud Analytics로 이동하든, Stitch에서 Qlik Talend Cloud로 이동하든, 마이그레이션 센터은 새로운 환경으로 전환할 때의 프로세스와 모범 사례에 대한 지침을 제공합니다.
기타 Qlik 솔루션
Qlik 클라이언트 관리 솔루션(온프레미스)에 대한 지원이 필요한 경우 다른 Qlik 도움말 시스템에 대한 직접 링크가 있습니다.
- QlikView
- Qlik Sense Enterprise on Windows(사용자)
- Qlik Sense Enterprise on Windows(관리자) (영어로만 제공)
- Qlik Sense Enterprise on Windows(개발자) (영어로만 제공)
- Qlik NPrinting
- Qlik Replicate (영어로만 제공)
- Qlik Compose (영어로만 제공)
Qlik 클라이언트 관리 솔루션에 대한 설명서를 검토하려면 Qlik 도움말 홈 페이지를 방문하십시오.