
Modèle de données chargées en mémoire
Dans le modèle de données chargées en mémoire de Qlik Sense, toutes les valeurs uniques des champs sélectionnés dans une table du script de chargement sont chargées dans des structures de champ, et les données associatives sont chargées simultanément dans la table. Les données de champ et les données associatives sont toutes conservées en mémoire.
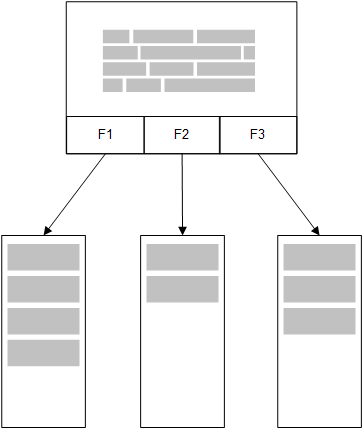
Si une deuxième table connexe était chargée en mémoire, elle aurait un champ en commun avec la première table. De plus, cette deuxième table pourrait ajouter de nouvelles valeurs uniques au champ commun ou partager des valeurs existantes.
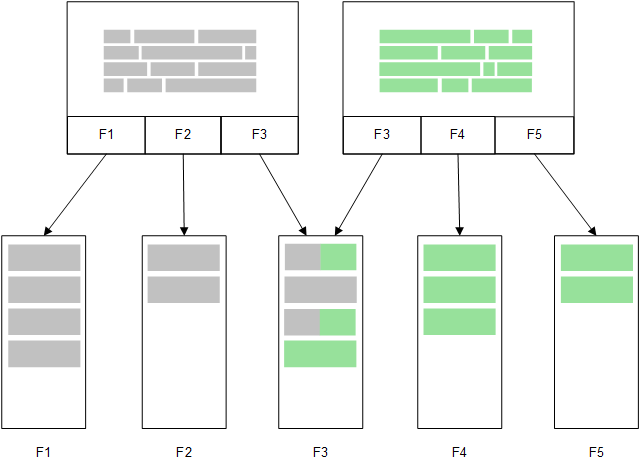
Direct Discovery
Lorsque des champs de table sont chargés à l'aide d'une instruction Direct Discovery LOAD (Direct Query), une table similaire comportant uniquement les champs de type DIMENSION est créée. Tout comme pour les champs chargés en mémoire, les valeurs uniques des champs de type DIMENSION sont chargés en mémoire. Cependant, les associations entre les champs sont conservées dans la base de données.
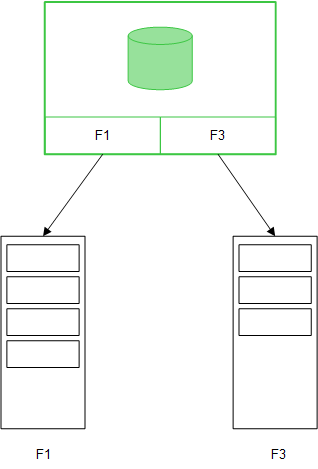
Les valeurs des champs MEASURE sont également conservées dans la base de données.
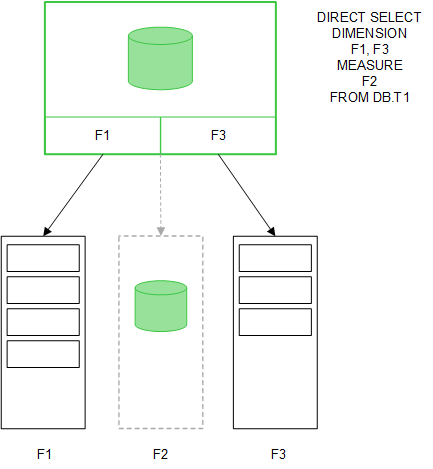
Dès lors que la structure Direct Discovery est établie, vous pouvez utiliser les champs Direct Discovery avec certains objets de visualisation et les employer pour créer des associations avec des champs chargés en mémoire. Lorsqu'un champ Direct Discovery est utilisé, Qlik Sense crée automatiquement la requête SQL appropriée à exécuter sur les données externes. Lorsque vous effectuez des sélections, les valeurs de données associées des champs Direct Discovery sont utilisées dans les conditions WHERE des requêtes de base de données.
Avec chaque sélection, les visualisations contenant des champs Direct Discovery sont recalculées. Les calculs ont lieu dans la table de la base de données source via l'exécution de la requête SQL créée par Qlik Sense. La fonction de condition de calcul permet de spécifier les situations dans lesquelles les visualisations doivent être recalculées. Tant que la condition n'est pas remplie, Qlik Sense n'envoie pas de requêtes pour recalculer les visualisations.
Différences de performances entre les champs chargés en mémoire et les champs Direct Discovery
Le traitement en mémoire est toujours plus rapide que le traitement dans les bases de données source. Les performances de Direct Discovery reflètent celles du système exécutant la base de données chargée de traiter les requêtes Direct Discovery.
Il est possible d'appliquer à Direct Discovery les meilleures pratiques d'optimisation des requêtes et bases de données standard. Il est recommandé de procéder à toutes les tâches d'optimisation des performances au niveau de la base de données source. Direct Discovery ne prend pas en charge l'optimisation des performances de requêtes à partir de l'application Qlik Sense. Il est toutefois possible d'émettre des appels parallèles asynchrones en direction de la base de données en utilisant la fonction de regroupement de connexions. Syntaxe du script de chargement permettant de configurer la fonction de regroupement :
SET DirectConnectionMax=10;
La fonction de mise en cache de Qlik Sense permet également d'améliorer le confort d'utilisation global. Voir Mise en cache et Direct Discovery ci-dessous.
Il est également possible d'améliorer les performances de Direct Discovery avec les champs de type DIMENSION en détachant certains champs des associations. Pour ce faire, vous devez appliquer le mot-clé DETACH à DIRECT QUERY. Même si les champs détachés ne sont pas interrogés concernant les associations, ils font tout de même partie des filtres, permettant ainsi d'accélérer les temps de sélection.
Même si les champs Qlik Sense chargés en mémoire et les champs Direct Discovery de type DIMENSION conservent tous leurs données en mémoire, leur mode de chargement a des répercussions sur la vitesse de chargement en mémoire. Les champs chargés en mémoire Qlik Sense conservent seulement une copie de la valeur d'un champ lorsqu'il existe plusieurs instances de la même valeur. Cependant, toutes les données de champ sont chargées et les données en double sont triées et éliminées.
Les champs DIMENSION stockent également une seule copie de la valeur d'un champ, mais les valeurs en double sont triées au niveau de la base de données, avant leur chargement en mémoire. Lorsque vous manipulez de grandes quantités de données, comme cela arrive fréquemment dans le cadre de l'utilisation de Direct Discovery, les données sont chargées bien plus rapidement sous forme de chargement DIRECT QUERY qu'elles le seraient via un chargement SQL SELECT utilisé pour les champs en mémoire.
Différences entre les données chargées en mémoire et les données de base de données
DIRECT QUERY respecte la casse des caractères lorsqu'il crée des associations avec des données chargées en mémoire. Direct Discovery sélectionne les données des bases de données source en fonction de la sensibilité à la casse des champs de base de données interrogés. Si les champs de base de données ne respectent pas la casse, une requête Direct Discovery risque de renvoyer des données qu'une requête de type « en mémoire » ne renverrait pas. Si, par exemple, une base de données non sensible à la casse contenait les données suivantes, une requête Direct Discovery portant sur la valeur "Red" renverrait les quatre lignes.
| Colonne A | Colonne B |
|---|---|
| red | one |
| Red | two |
| rED | three |
| RED | four |
Une sélection de type « en mémoire » de la valeur "Red," en revanche, renverrait seulement :
Red two
Qlik Sense normalise les données jusqu'à un point où certains résultats générés sur les données sélectionnées n'auraient aucune correspondance dans les bases de données. De ce fait, une requête de type « en mémoire » peut générer plus de résultats qu'une requête Direct Discovery. Par exemple, dans le tableau suivant, les valeurs du chiffre "1" varient en fonction de l'emplacement des espaces environnants :
| Colonne A | Colonne B |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
| '2' | two |
Si vous sélectionnez "1" dans un volet de filtre pour la colonne intitulée ColumnA, où les données sont de type « en mémoire » Qlik Sense standard, les trois premières lignes sont associées :
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
Si le volet de filtre contient des données Direct Discovery, il se peut que la sélection de "1" associe uniquement "no_space". Les correspondances renvoyées pour les données Direct Discovery dépendent de la base de données. Certaines renvoient uniquement "no_space" tandis que d'autres, comme SQL Server, renvoient "no_space" et "space_after".
Mise en cache et Direct Discovery
La fonction de mise en cache de Qlik Sense stocke en mémoire les états de sélection des requêtes et les résultats associés. Comme les mêmes types de sélection sont effectués, Qlik Sense utilise la requête mise en cache au lieu d'interroger les données source. Lorsqu'une sélection différente est effectuée, une requête SQL porte sur la source de données. Les résultats mis en cache sont partagés entre les utilisateurs.
-
L'utilisateur applique la sélection initiale.
SQL est transmis à la source de données sous-jacente.
-
L'utilisateur efface la sélection et applique la même sélection qu'au départ.
Le résultat du cache est renvoyé ; SQL n'est pas transmis à la source de données sous-jacente.
-
L'utilisateur applique une sélection différente.
SQL est transmis à la source de données sous-jacente.
Il est possible de définir une limite temporelle pour la mise en cache à l'aide de la variable système DirectCacheSeconds. Dès que cette limite temporelle est atteinte, Qlik Sense efface du cache les résultats des requêtes de Direct Discovery générés pour les sélections précédentes. Qlik Sense recherche ensuite les sélections dans les données source et recrée le cache pour la durée limite spécifiée.
La période de mise en de cache par défaut des résultats de requête Direct Discovery est de 30 minutes, à moins que la variable système DirectCacheSeconds soit utilisée.