
Model voor opslag in het geheugen
In het model voor opslag in het geheugen van Qlik Sense worden alle unieke waarden in de velden die zijn geselecteerd in een tabel in het load-script in veldstructuren geladen en worden de associatieve gegevens tegelijkertijd in de tabel geladen. De veldgegevens en de associatieve gegevens worden allemaal in het geheugen opgeslagen.
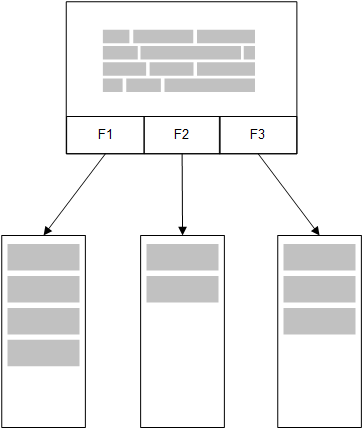
Een tweede, gerelateerde tabel die in het geheugen wordt geladen deelt een gemeenschappelijk veld en die tabel voegt mogelijk nieuwe unieke waarden aan het gemeenschappelijke veld of deelt bestaande waarden.
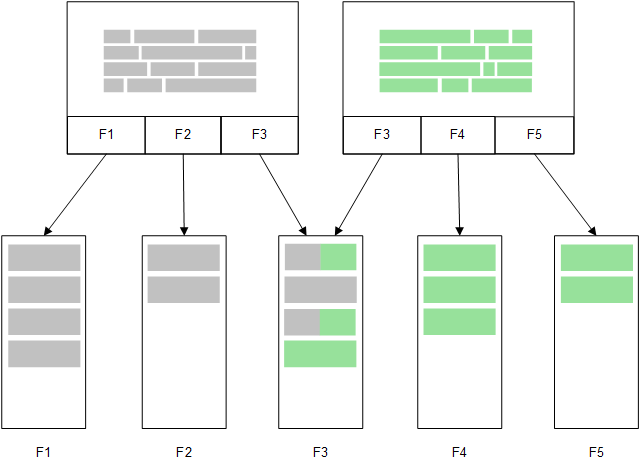
Direct Discovery
Wanneer tabelvelden worden geladen met een Direct Discovery LOAD-instructie (Direct Query), wordt een vergelijkbare tabel gemaakt met alle en de DIMENSION-velden. Net als bij de velden in het geheugen worden de unieke waarden voor de DIMENSION-velden in het geheugen geladen. Maar de associaties tussen de velden blijven bestaan in de database.
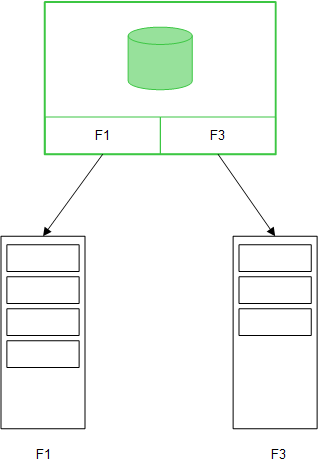
MEASURE-veldwaarden blijven eveneens bewaard in de database.
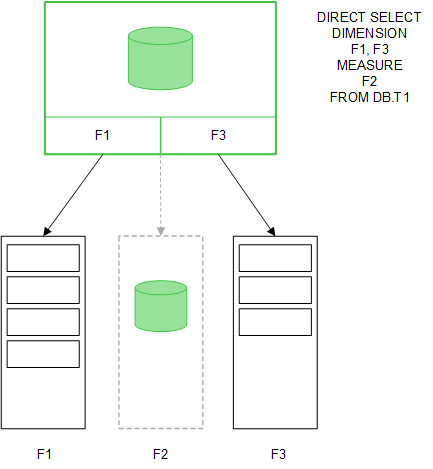
Zodra de Direct Discovery-structuur is vastgesteld, kunnen de Direct Discovery-velden worden gebruikt in combinatie met bepaalde visualisatieobjecten en kunnen zij worden gebruikt voor associaties met velden in het geheugen. Als een Direct Discovery-veld wordt gebruikt, maakt Qlik Sense automatisch de juiste SQL-query om uit te voeren op de externe gegevens. Wanneer selecties worden uitgevoerd, worden de bijbehorende gegevenswaarden van de Direct Discovery-velden gebruikt in de WHERE-voorwaarden van de databasequery's.
Bij elke selectie worden de visualisaties metDirect Discovery-velden opnieuw berekend, waarbij de berekeningen plaatsvinden in de brondatabasetabel door het uitvoeren van de SQL-query die is gemaakt door Qlik Sense. De functie voor de berekeningsvoorwaarde kan worden gebruikt om aan te geven wanneer visualisaties opnieuw moeten worden berekend. Totdat aan de voorwaarde wordt voldaan, verzendt Qlik Sense geen query's om de visualisaties opnieuw te berekenen.
Prestatieverschillen tussen velden in het geheugen en Direct Discovery-velden
Verwerking in het geheugen is altijd sneller dan verwerking in brondatabases. De prestaties van Direct Discovery geven de prestaties van het systeem aan waarop de database wordt uitgevoerd die de Direct Discovery-query's verwerkt.
Het is mogelijk om de standaard aanbevolen procedures te gebruiken voor afstemming van databases en query's in Direct Discovery. Alle prestatieafstemmingen moeten plaatsvinden op de brondatabase. Direct Discovery biedt geen ondersteuning voor prestatieafstemmingen voor query's vanuit de Qlik Sense-app. Het is echter mogelijk om asynchrone, parallelle aanroepen uit te voeren op de database door gebruik te maken van de voorziening voor verbindingsgroepering. De syntaxis van het load-script voor het instellen van de groeperingsvoorziening is als volgt:
SET DirectConnectionMax=10;
Caching in Qlik Sense verbetert eveneens de algehele gebruikerservaring. Zie Caching en Direct Discovery hieronder.
De prestaties van Direct Discovery met DIMENSION-velden kunnen tevens worden verbeterd door sommige velden los te koppelen van hun associaties. Dit wordt gedaan met het trefwoord DETACH in DIRECT QUERY. Hoewel geen query's worden uitgevoerd op losgekoppelde velden, maken deze wel deel uit van de filters, waardoor de selectie wordt versneld.
Hoewel velden in het geheugen van Qlik Sense en Direct Discovery DIMENSION-velden beide hun gegevens in het geheugen hebben opgeslagen, is de manier waarop zij worden geladen van invloed op de snelheid van de laadbewerkingen in het geheugen. Velden in het geheugen van Qlik Sense bewaren slechts één kopie van een veldwaarde wanneer er meerdere exemplaren van dezelfde waarde zijn. Alle veldgegevens worden echter geladen, waarna de dubbele gegevens worden uitgesorteerd.
DIMENSION-velden slaan eveneens slechts één exemplaar van een veldwaarde op, maar de dubbele waarden worden uitgesorteerd in de database voordat ze in het geheugen worden geladen. Wanneer u te maken hebt met grote hoeveelheden gegevens, zoals meestal het geval is bij het gebruik van Direct Discovery, worden de gegevens veel sneller geladen als DIRECT QUERY-laadbewerking dan via de SQL SELECT-laadbewerking die wordt gebruikt voor velden in het geheugen.
Verschillen tussen de gegevens in het geheugen en databasegegevens
DIRECT QUERY is hoofdlettergevoelig bij het uitvoeren van associaties met gegevens in het geheugen. Direct Discovery selecteert gegevens uit brondatabases op basis van de hoofdlettergevoeligheid van de databasevelden in query's. Als de databasevelden niet hoofdlettergevoelig zijn, geeft een Direct Discovery-query mogelijk gegevens als resultaat die een query in het geheugen niet zou retourneren. Als bijvoorbeeld de volgende gegevens bestaan in een database die niet hoofdlettergevoelig is, levert een Direct Discovery-query van de waarde "Red" alle vier de rijen als resultaat op.
| ColumnA | ColumnB |
|---|---|
| red | one |
| Red | two |
| rED | three |
| RED | four |
Een selectie in het geheugen van "Red,", daarentegen, resulteert uitsluitend in:
Red two
Qlik Sense normaliseert gegevens in een mate die overeenkomsten oplevert bij geselecteerde gegevens die databases niet zouden opleveren. Het resultaat is dat een query in het geheugen meer overeenkomende waarden oplevert dan een Direct Discovery-query. In de volgende tabel verschillen de waarden voor het getal "1" bijvoorbeeld op basis van de locatie van spaties er omheen:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
| '2' | two |
Als u "1" selecteert in een filtervak voor ColumnA, waarbij de gegevens zich standaard in het geheugen van Qlik Sense bevinden, zijn de eerste drie rijen gekoppeld:
| ColumnA | ColumnB |
|---|---|
| ' 1' | space_before |
| '1' | no_space |
| '1 ' | space_after |
Indien het filtervak Direct Discovery-gegevens bevat, wordt bij de selectie van "1" mogelijk alleen "no_space" gekoppeld. De overeenkomsten die worden geretourneerd voor Direct Discovery-gegevens zijn afhankelijk van de database. Sommige retourneren uitsluitend"no_space" terwijl andere, zoals SQL Server, "no_space" en "space_after" als resultaat opleveren.
Caching en Direct Discovery
Bij Qlik Sense-caching worden selectiestatussen van query's en de gekoppelde queryresultaten in het geheugen opgeslagen. Als dezelfde typen selecties worden gemaakt, voert Qlik Sense de query uit vanuit de cache in plaats van vanuit de brongegevens. Wanneer een andere selectie plaatsvindt, wordt een SQL-query uitgevoerd op de gegevensbron. De resultaten in de cache worden door de gebruikers gedeeld.
Voorbeeld:
-
Gebruiker voert eerste selectie uit.
SQL wordt doorgegeven via de onderliggende gegevensbron.
-
Gebruiker wist selectie en past dezelfde selectie toe als eerste selectie.
Het resultaat in de cache wordt geretourneerd, SQL wordt niet doorgegeven via de onderliggende gegevensbron.
-
Gebruiker voert andere selectie uit.
SQL wordt doorgegeven via de onderliggende gegevensbron.
Er kan een tijdslimiet worden ingesteld voor caching met de systeemvariabele DirectCacheSeconds. Zodra de tijdslimiet is bereikt, wist Qlik Sense de cache voor de Direct Discovery-queryresultaten die zijn gegenereerd voor de vorige selecties. Qlik Sense zoekt vervolgens in de brongegevens naar de selecties en maakt de cache opnieuw voor de aangegeven tijdslimiet.
De standaard cachetijd voor Direct Discovery-queryresultaten bedraagt 30 minuten, tenzij gebruik wordt gemaakt van de systeemvariabele DirectCacheSeconds.