Application Talend Data Catalog
| Fonctionnalité | Description |
|---|---|
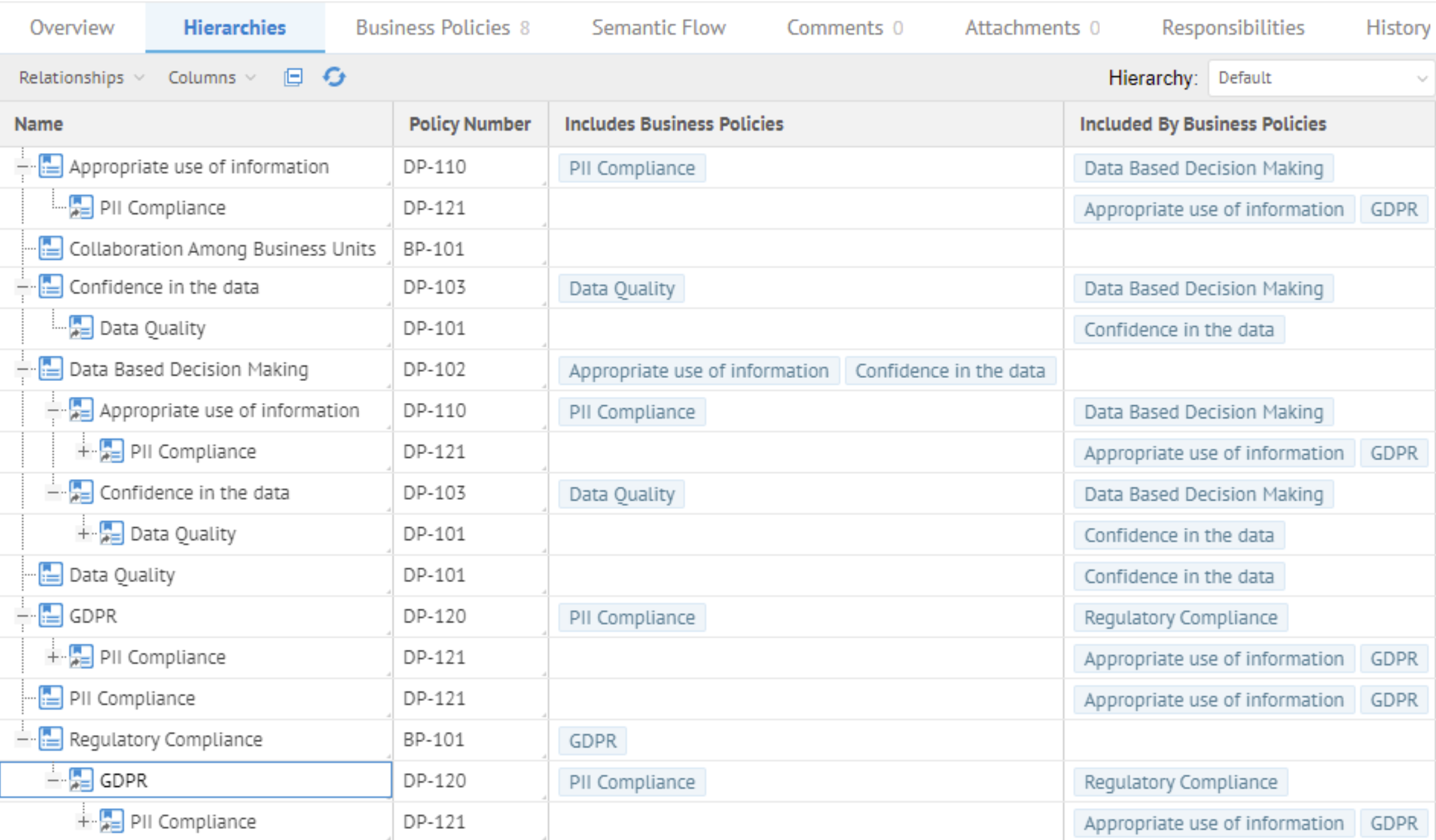
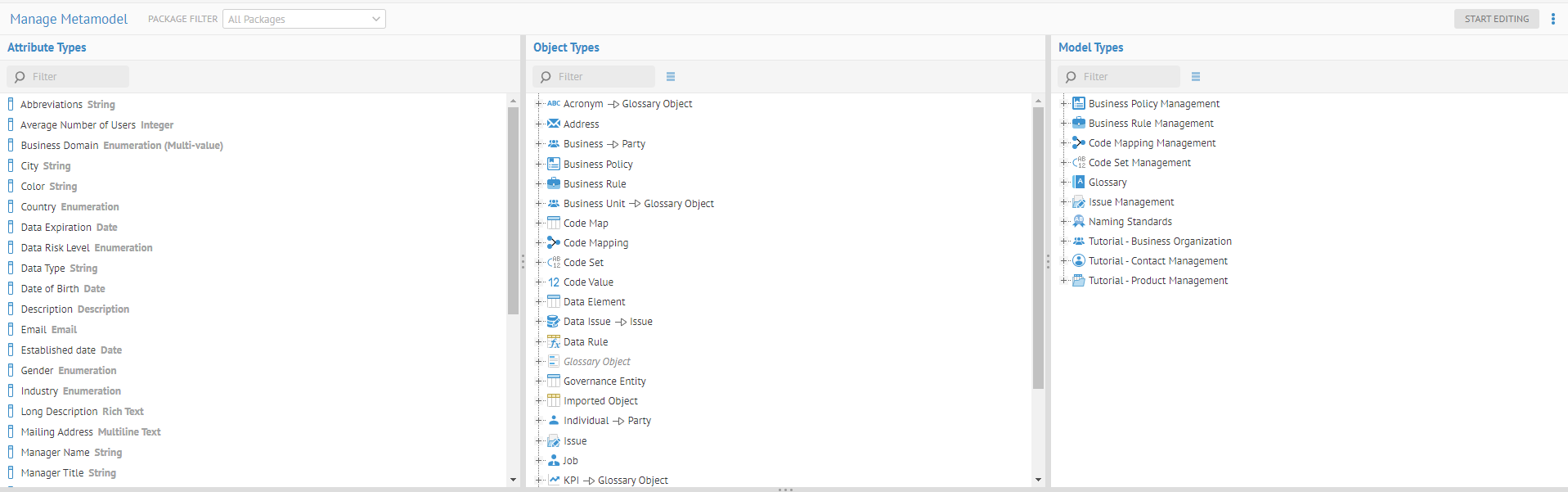
| Nouvelle gestion des métamodèles | Avec la nouvelle fonctionnalité de gestion des métamodèles, vous pouvez définir des modèles personnalisés et étendre des modèles importés pour la gestion de données, comme les données de référence, la qualité de données, la sécurité des données, la gestion des problèmes de données, les règles et stratégies métier, la modélisation des processus métier et les améliorations ou la conformité aux règles. La fonctionnalité de métamodélisation est disponible à partir de la page Manage Metamodel (Gestion du métamodèle).
|
| Nouveaux modèles métier personnalisés | Vous pouvez utiliser la nouvelle fonctionnalité de métamodélisation pour définir des modèles personnalisés, comme des modèles associés aux données de référence, stratégies métier et gestions des règles ou gestions des problèmes de données. Les modèles personnalisés sont des instanciations d'un type de modèle personnalisé défini dans la page Manage Metamodel (Gérer le métamodèle). Talend Data Catalog fournit une fonctionnalité de modélisation d'objet et une fonctionnalité d'édition graphique des diagrammes des classes UML pour ces modèles personnalisés. Talend Data Catalog fournit également des modèles métier standards et système et des extensions de modèles. Le package Standard comprend à présent le modèle de glossaire avec de nouveaux objets KPI (Indicateur clé de performance) et Acronym (Acronyme). Une fois défini, vous pouvez utiliser les fonctionnalités disponibles pour les modèles importés sur les modèles personnalisés, y compris les entrées de données, les analyses et les rapports, à l'aide de feuilles de travail et de dashboards.
|
| Nouvelles extensions de modèles techniques importés | Vous pouvez utiliser la nouvelle fonctionnalité de métamodélisation pour étendre la documentation de données des modèles importés. Les modèles importés sont les modèles associés à un pont d'import et alimentés via le processus de collecte.
|
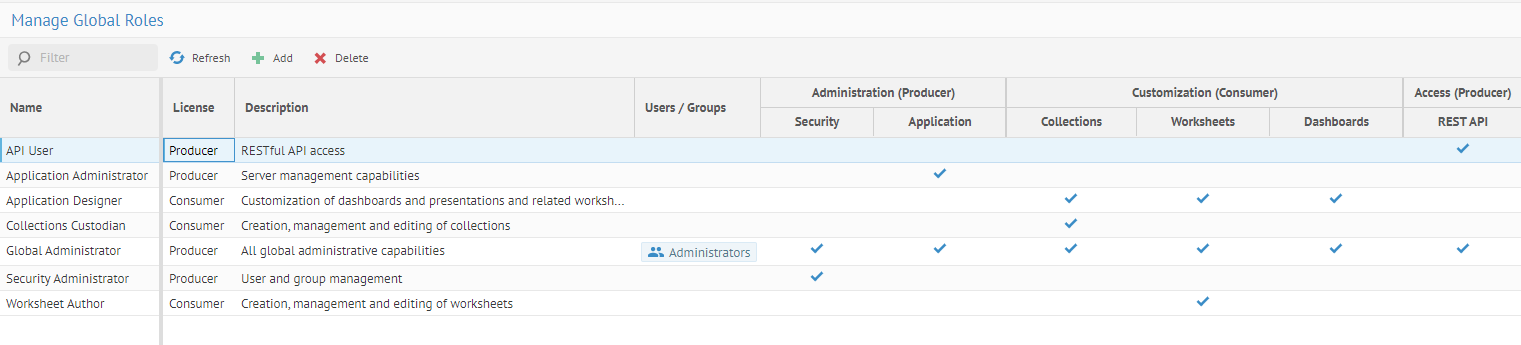
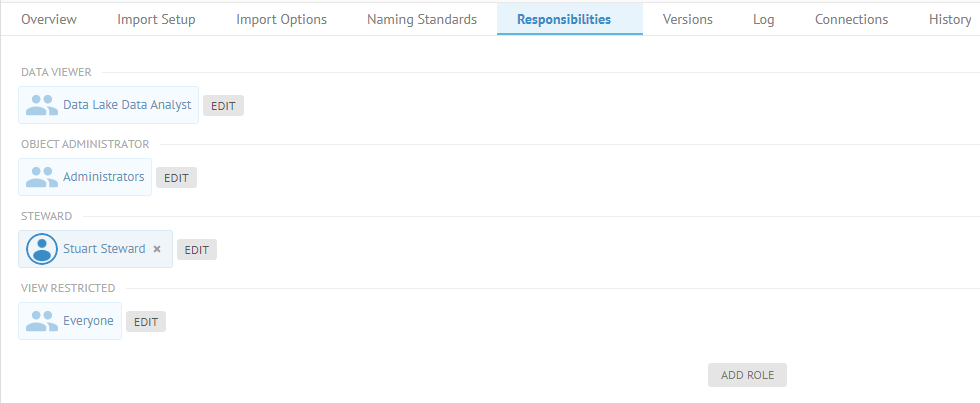
| Nouveau contrôle des accès basé sur les rôles avec rôles globaux et rôles d'objets | Talend Data Catalog fournit à présent un contrôle des accès basé sur les rôles.
|
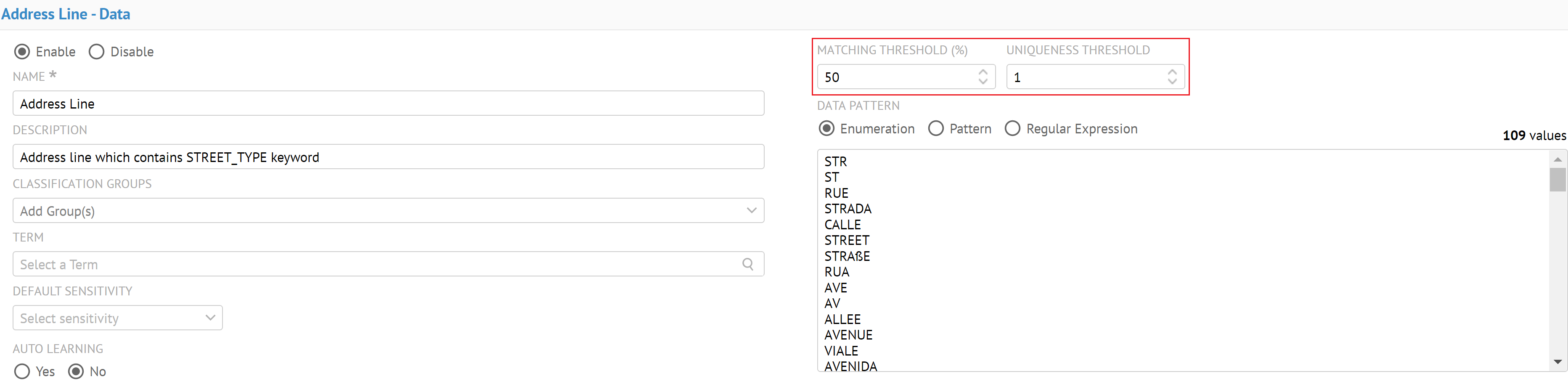
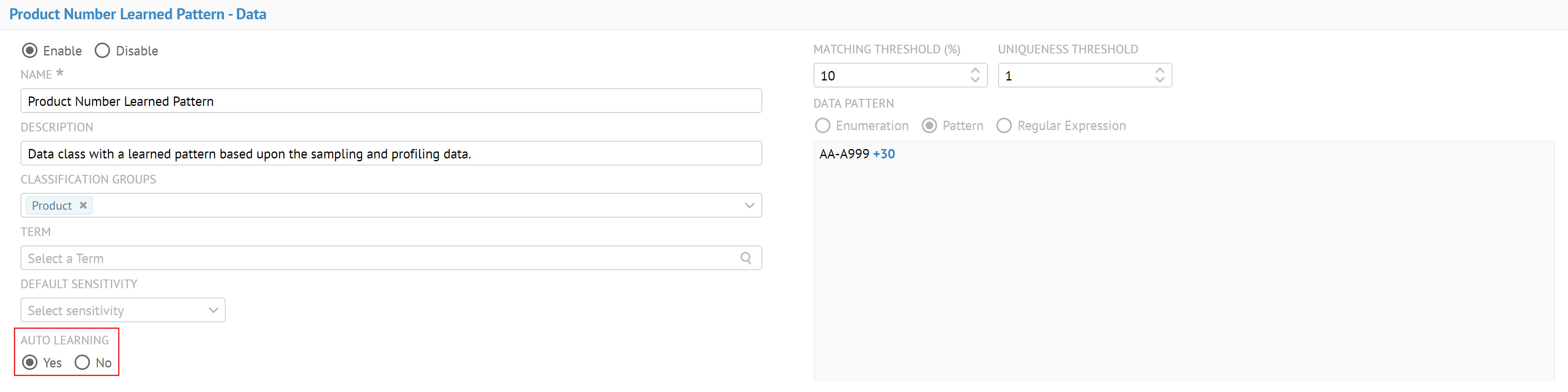
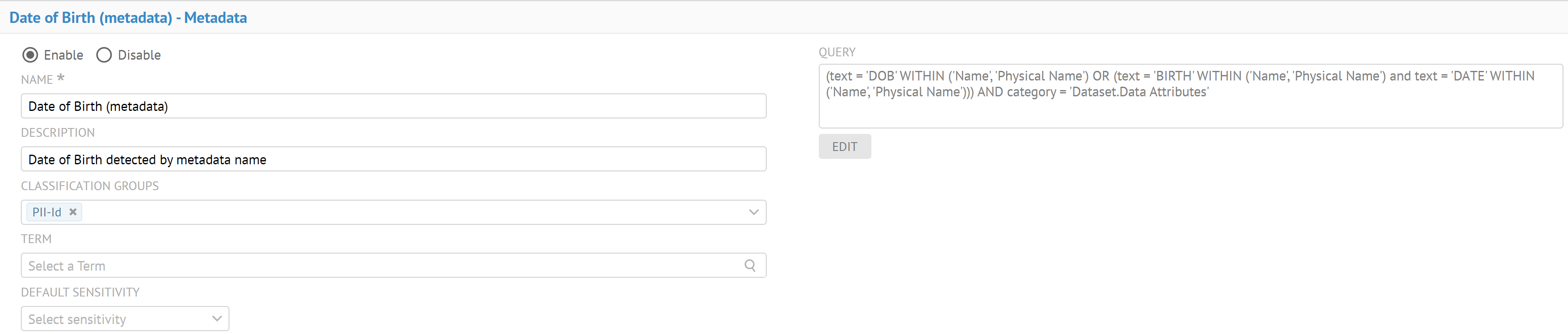
| Nouvelle classification de données | La classification de données vous permet de détecter, de comprendre et de classifier la nature et l'objectif des éléments contenus dans les sources de données importées dans votre catalogue. Les classes de données remplacent à présent les types sémantiques. Vous pouvez gérer les classes de données depuis la nouvelle page Manage Data Classes (Gérer les classes de données).
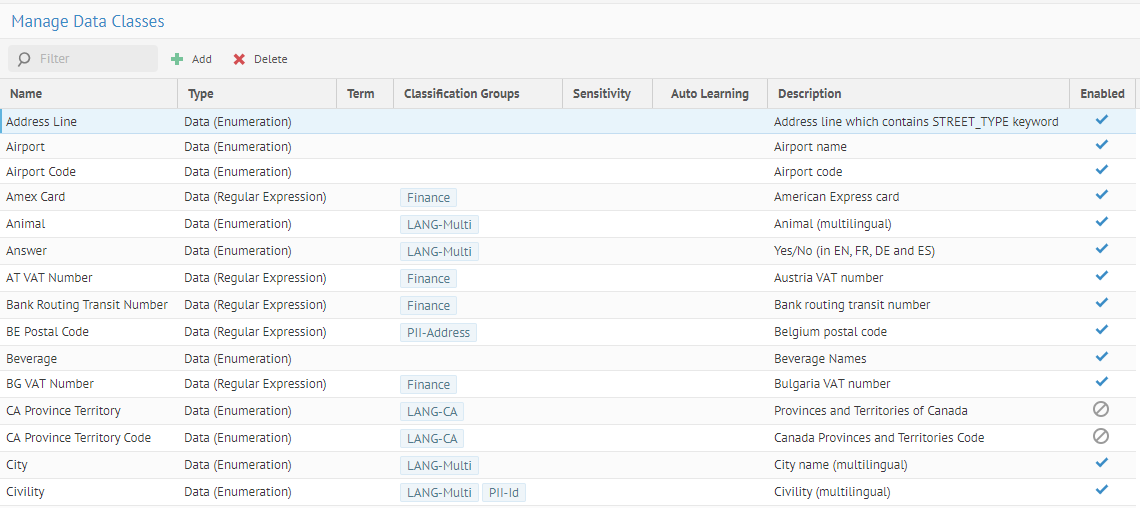
Il y a plusieurs types de classes de données :
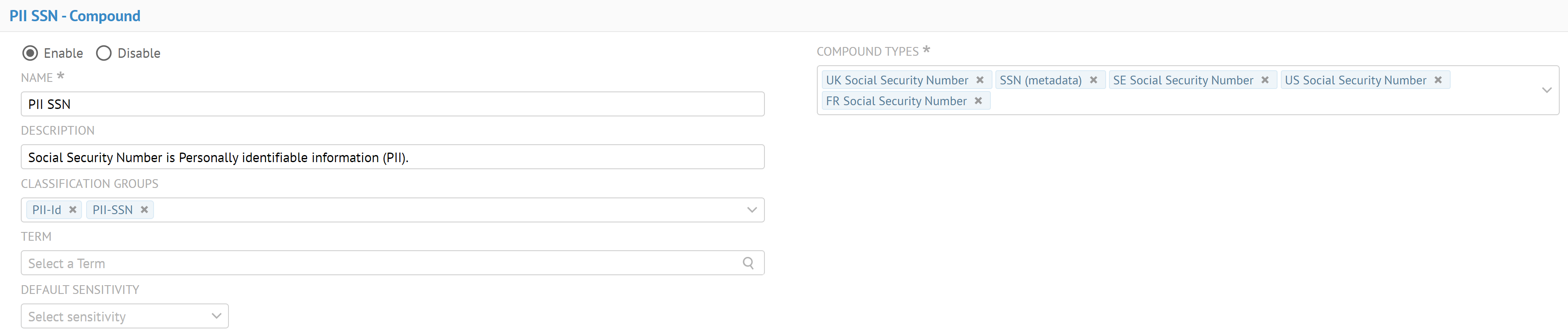
Talend Data Catalog fournit de nouvelles classes de données sensibles de type Données, Métadonnées et Composé pour vous permettre d'identifier et masquer facilement les données sensibles.
|
| Nouveaux libellés de sensibilité | Les nouveaux libellés de sensibilité vous permettent d'identifier les données sensibles. Vous pouvez voir une nouvelle icône Sensitivity Label (Libellé de sensibilité) en haut à droite des pages de détails de l'objet.
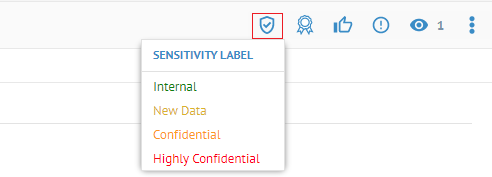
Vous pouvez gérer et personnaliser ces libellés depuis la page Manage Sensitivity Labels (Gérer les libellés de sensibilité).

Vous pouvez appliquer ces libellés en attribuant manuellement des mots-clés à chaque objet, en utilisant la fonctionnalité d'édition de masse dans les feuilles de travail, en utilisant la détection automatique de classification de données ou en utilisant les libellés de sensibilité déduits. |
| Nouveaux libellés conditionnels | Vous pouvez définir de nouveaux libellés conditionnels basés sur le langage MQL (Metadata Query Language), par exemple un libellé "Highly Commented" pour les objets ayant plus de cinq commentaires. Vous pouvez gérer et créer ces libellés depuis la page Manage Conditional Labels (Gérer les libellés conditionnels).
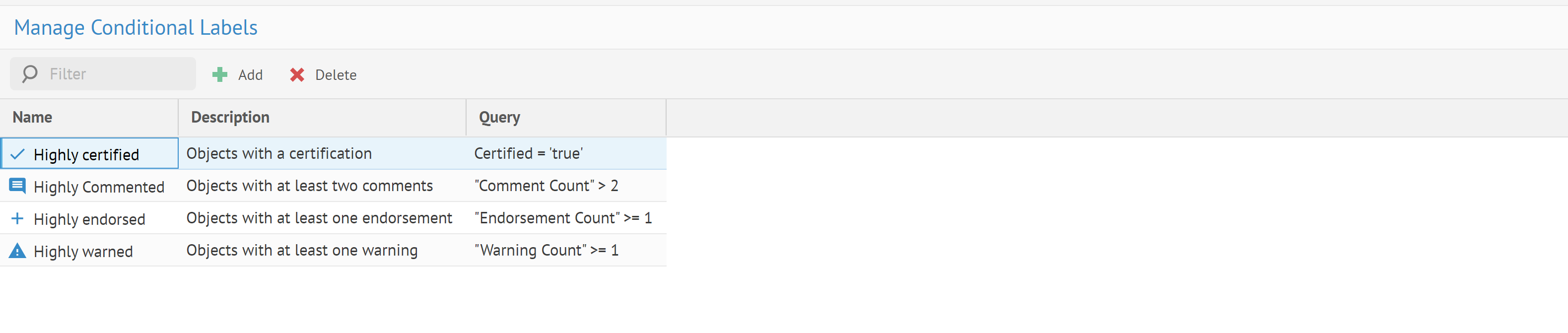
Vous pouvez voir les libellés conditionnels dans la zone Conditional Labels (Libellés conditionnels) depuis l'onglet de vue d'ensemble des pages de détails des objets.

Les libellés conditionnels peuvent être affichés dans des résultats de recherche, des feuilles de travail ou des diagrammes de lignage de flux de données. |
| Nouvelle gestion des libellés | Vous pouvez à présent vérifier ou supprimer l'attribution des libellés depuis la page Manage Labels (Gérer les libellés).
Par défaut, vous pouvez voir tous les libellés dans le référentiel depuis la vue All Labels (Tous les libellés). Vous pouvez également voir les libellés attribués aux objets dans la configuration courante depuis la vue Configuration Labels (Libellés de configuration). |
| Nouveautés : observateur·trice d'objet et notifications par e-mail | Les nouvelles notifications des observateur·trices vous permettent d'informer les observateur·trices lorsque certains événements se produisent sur cet objet. Vous pouvez activer les notifications par e-mail pour les observateur·trices côté serveur depuis la page Manage Email (Gérer les e-mails).
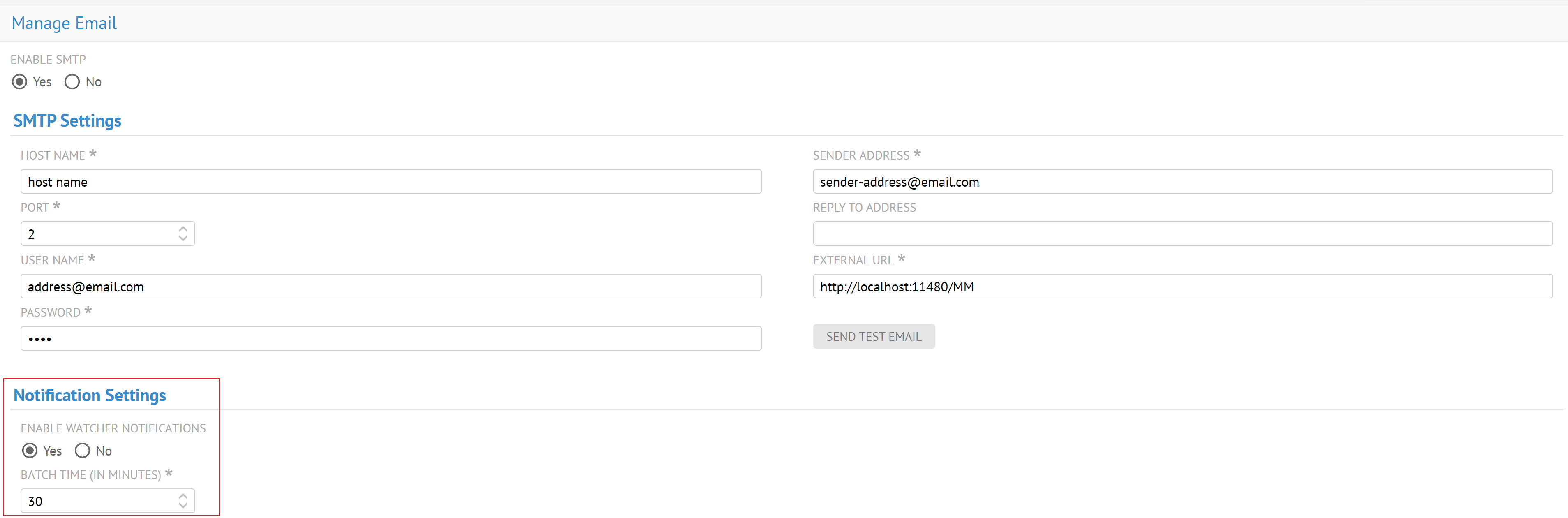
Vous pouvez configurer les fonctionnalités de modification et de gestion des observateur·trices via les rôles d'objets dans la page Manage Object Roles (Gérer les rôles d'objets). Vous pouvez configurer la fréquence de notification pour les observateur·trices à partir de la page Manage Users (Gestion des utilisateur·trices) ou User Profile (Profil utilisateur). Vous pouvez configurer une nouvelle icône d'observateur·trice en haut à droite des pages d'objets. Le menu vous permet de démarrer ou arrêter l'observation d'un objet, de voir le nombre d'observateur·trices ou de gérer les observateur·trices d'un objet.
Cette fonctionnalité est disponible pour les modèles importés et les modèles personnalisés. Elle est disponible uniquement au niveau des modèles et des sous-modèles, si le modèle est un multimodèle.
Vous pouvez recevoir un e-mail avec les statistiques résumées des modifications et un lien vers le rapport de comparaison de versions d'un modèle. Vous pouvez également recevoir des e-mails de notification selon votre rôle et vos attributions de fonctionnalités pour les transitions de workflows, les modifications de configurations ou les erreurs de serveur. |
| Nouvelle fonctionnalité de stockage des identifiants dans des gestionnaires de secrets (Secret Manager) Cloud | Vous pouvez à présent stocker les identifiants du pont, par exemple l'utilisateur, le mot de passe ou la clé privée dans un gestionnaire de secrets, en utilisant la nouvelle page Manage Secret Vaults (Chambres fortes de secrets).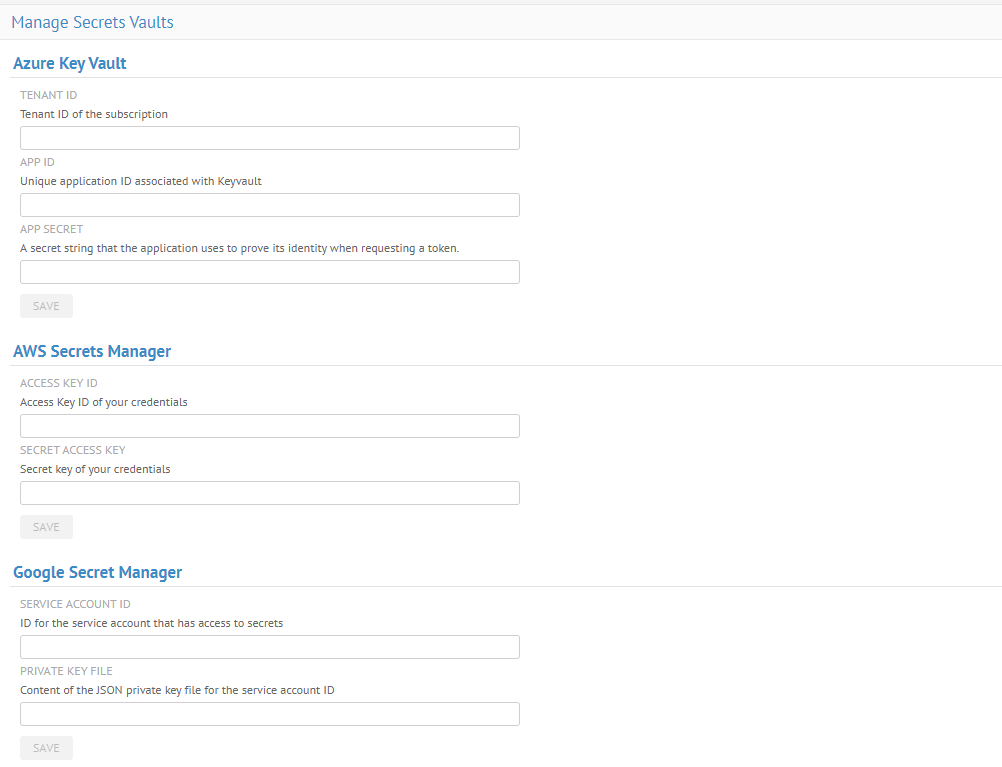
Talend Data Catalog supporte les gestionnaires de secrets suivants :
|
| Amélioration de l'automatisation et de la productivité de la documentation de données | La documentation de données vous permet de définir les données techniques en des termes métier compréhensibles par tout le monde. Il y a maintenant plusieurs catégories de documentation de données :
Vous pouvez voir de nouveaux assistants de documentation métier, de terme, mappée ou déduite dans l'onglet Overview (Vue d'ensemble) de la page d'objet. Talend Data Catalog peut vous suggérer des noms métier basés sur les noms techniques, en utilisant les standards de nommage et les fonctionnalités d'apprentissage supervisé. Elle peut également suggérer une description métier depuis la documentation déduite.

Vous pouvez créer de nouveaux widgets graphiques d'indicateurs clés de performance sur la couverture de la documentation de données en utilisant les nouveaux attributs Term Documentation (Documentation de terme) et Inferred Documentation (Documentation déduite), disponibles dans les API REST, le MQL, les feuilles de travail et les dashboards. |
| Nouvelle fonctionnalité de tri des dates de mise à jour | Vous pouvez trier les résultats par date de mise à jour dans l'explorateur d'objets, les feuilles de travail ou vos recherches.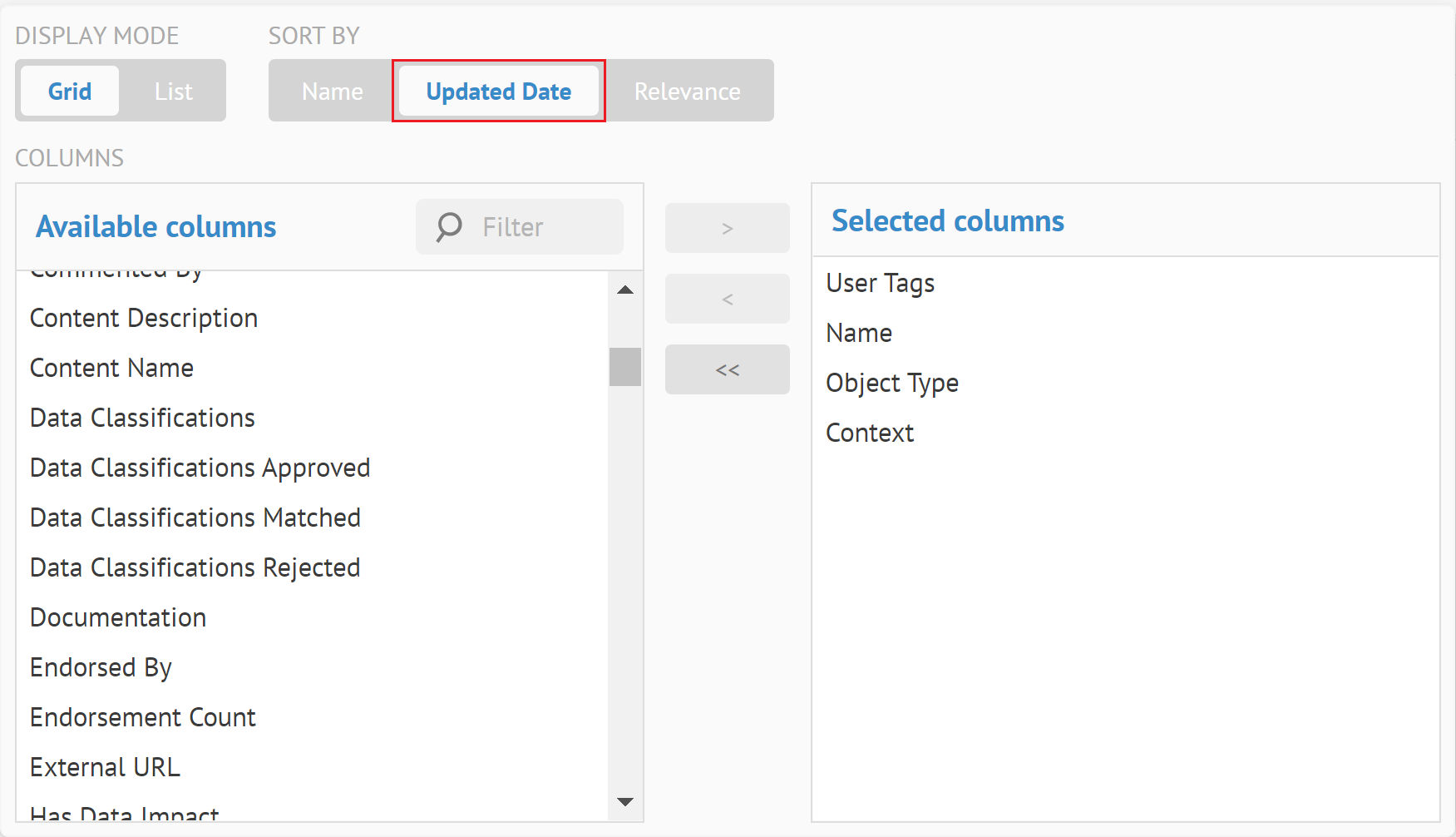
|
| Amélioration de l'architecture du profiling et de l'échantillonnage de données | Les résultats de l'échantillonnage et du profiling de données collectés par les serveurs de collecte distants sont à présent sauvegardés côté serveur. Vous pouvez avoir une mise à jour automatique ou à la demande de l'échantillonnage ou du profiling de données, par exemple après la création d'une classe de données, sans avoir à retourner sur les serveurs de collecte distants. |
| Amélioration du reporting et des présentations des métadonnées | Vous pouvez à présent importer et exporter des présentations par défaut entre les serveurs à partir de la page Manage Default Presentations (Gérer les présentations par défaut). De nouveaux widgets graphiques sont disponibles pour les présentations des pages des détails des objets. |
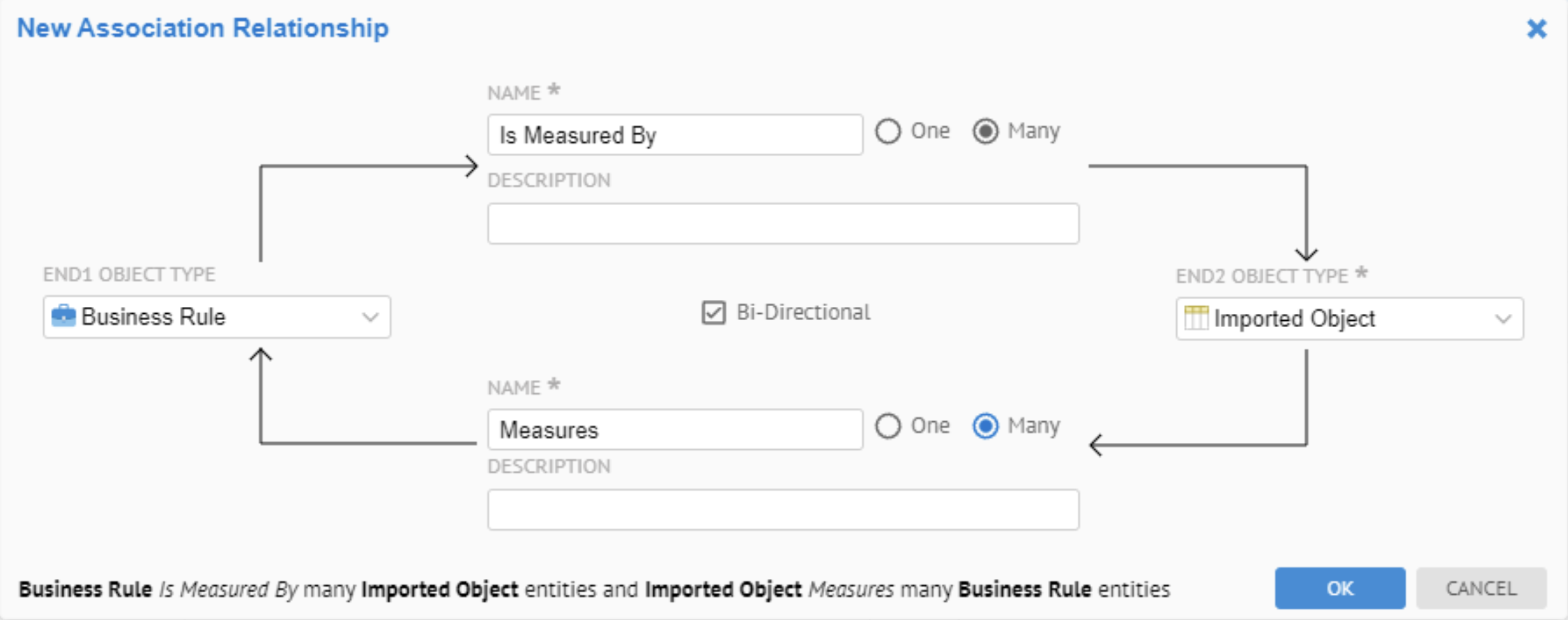
| Amélioration des fonctionnalités d'API REST | Les nouvelles fonctionnalités sont disponibles dans l'API REST :
Pour plus d'informations, cliquez sur le lien Consulter la documentation générale dans la page de documentation de l'API REST Talend Data Catalog. |
| Amélioration du langage MQL (Metadata Query Language) | Vous n'avez plus besoin d'utiliser la syntaxe des caractères spéciaux sur les attributs lors de l'utilisation du langage MQL dans vos rapports, dashboards ou feuilles de travail. La fonctionnalité de reporting dans les feuilles de travail et les dashboards a été améliorée : nouveaux objets système supportés relatifs à l'échantillonnage, au profiling, à la classification de données, aux rôles globaux et d'objets et aux actions de workflows. Vous pouvez consulter l'entrée New worksheet attributes (Nouveaux attributs de feuille de travail) ci-dessous pour voir les nouveaux attributs système disponibles pour les requêtes. Pour plus d'informations, cliquez sur le lien Consulter la documentation générale dans la page de documentation de l'API REST Talend Data Catalog. |
| Nouveaux attributs des feuilles de travail |
|
| Logiciel tiers et open source | Tous les logiciels tiers et open source ont été mis à niveau dans leur dernière version pour une meilleure sécurité et protection contre des vulnérabilités. |
| Amélioration de sécurité |
|
| Amélioration de la fonctionnalité d'export vers CSV |
Les fichiers CSV exportés sont améliorés pour contenir l'indicateur d'ordre des octets (Byte Order Mark, BOM). |