Comparaison de colonnes identiques dans différentes tables
Big Data Platform
Cloud API Services Platform
Cloud Big Data Platform
Cloud Data Fabric
Cloud Data Management Platform
Data Fabric
Data Management Platform
Data Services Platform
Qlik Talend Cloud Enterprise Edition
Qlik Talend Cloud Premium Edition
Real-Time Big Data Platform
Dans votre Studio Talend, vous pouvez créer une analyse comparant deux ensembles identiques de colonnes dans deux tables différentes. Cette analyse de redondance supporte uniquement les tables de bases de données.
Avant de commencer
Au moins une connexion à une base de données doit avoir été définie dans la perspective Profiling. Pour plus d'informations, consultez Se connecter à une base de données.
Dans cette vue, vous pouvez également accéder aux données actualisées via la perspective Data Explorer.
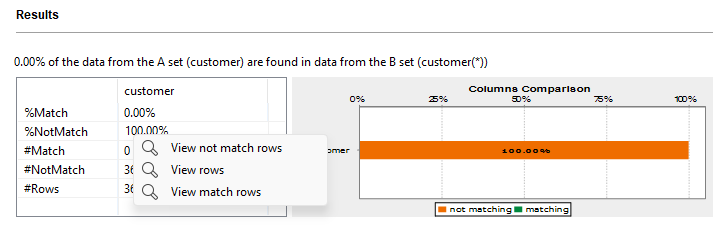
Pour accéder aux lignes de données analysées, cliquez-droit sur l'une des lignes de la table et sélectionnez une action à effectuer :
View match rows : pour accéder à une liste de toutes les lignes pouvant correspondre aux deux ensembles de colonnes identiques.
View not match rows : pour accéder à une liste de toutes les lignes ne pouvant pas correspondre aux deux ensembles de colonnes identiques.
View rows : pour accéder à une liste de toutes les lignes dans les deux ensembles de colonnes identiques.
Note InformationsAvertissement : L'explorateur de données ne supporte pas les connexions dont le nom d'utilisateur·trice est vide, par exemple avec l'authentification unique (SSO, Single Sign-On) de MS SQL Server. Si vous analysez des données à l'aide d'une de ces connexions et que vous essayez de visualiser les lignes et les valeurs des données dans la perspective Data Explorer, un message d'avertissement apparaît et vous demande de configurer vos informations de connexion au serveur SQL.
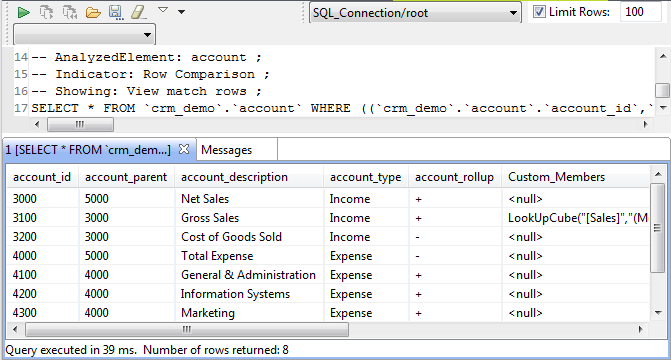
La capture d'écran ci-dessous montre la liste de toutes les lignes pouvant correspondre dans les deux ensembles, huit dans cet exemple.
Dans l'éditeur SQL, vous pouvez enregistrer la requête exécutée et l'afficher sous les nœuds Libraries (Bibliothèques) > Source Files (Fichiers sources) de la vue DQ repository (Référentiel DQ) si vous cliquez sur l'icône d'enregistrement dans la barre d'outils de l'éditeur. Pour plus d'informations, consultez Sauvegarder les requêtes exécutées sur les indicateurs.
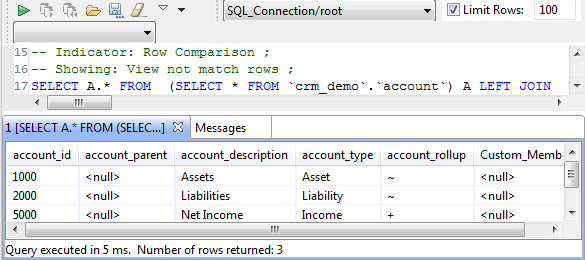
La capture d'écran ci-dessous illustre la liste de toutes les lignes ne pouvant correspondre dans les deux ensembles, trois dans cet exemple.
Définir l'analyse de redondance
Big Data Platform
Cloud API Services Platform
Cloud Big Data Platform
Cloud Data Fabric
Cloud Data Management Platform
Data Fabric
Data Management Platform
Data Services Platform
Qlik Talend Cloud Enterprise Edition
Qlik Talend Cloud Premium Edition
Real-Time Big Data Platform
Procédure
Dans la vue DQ repository (Référentiel DQ), développez le nœud Data Profiling (Profiling de données) et cliquez-droit sur Analyses > New analysis (Nouvelle analyse).
L'assistant Create new analysis (Créer une analyse) s'ouvre.
Sélectionnez Table > Redundancy Analysis (Analyse de redondance) et cliquez sur Create (Créer).
Dans le champ Name, saisissez un nom pour l'analyse.
Note InformationsImportant :
N'utilisez pas les caractères spéciaux suivants dans le nom des éléments : ~ ! ` # ^ * & \\ / ? : ; \ , . ( ) ¥ ' " « » < >
Ces caractères seront remplacés par un "_" dans le système de fichiers et vous risquez de créer des doublons.
Définissez les métadonnées de l'analyse (son objectif et sa description) dans les champs correspondants et cliquez sur Next (Suivant).
Sélectionner les colonnes à comparer
Big Data Platform
Cloud API Services Platform
Cloud Big Data Platform
Cloud Data Fabric
Cloud Data Management Platform
Data Fabric
Data Management Platform
Data Services Platform
Qlik Talend Cloud Enterprise Edition
Qlik Talend Cloud Premium Edition
Real-Time Big Data Platform
Procédure
Dans le menu Connection (Connexion), sélectionnez la connexion et cliquez sur Next (Suivant).
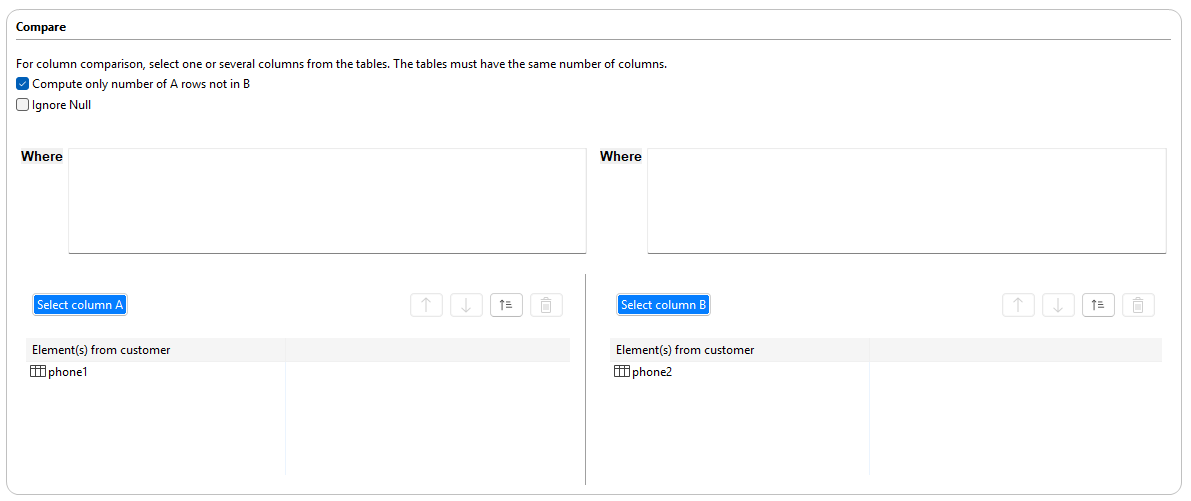
Dans le menu Compare (Comparer), sélectionnez les colonnes à comparer.
Dans cet exemple, vous souhaitez comparer des colonnes identiques dans les tables phone1 et phone2.
Cliquez sur Select column A (Sélectionner la colonne A) pour ouvrir la boîte de dialogue Column selection (Sélection de colonnes).
Parcourez les catalogues/schémas de votre connexion à la base de données pour atteindre la table contenant les colonnes que vous souhaitez analyser.
Vous pouvez filtrer la liste des tables ou colonnes en saisissant le texte de votre choix dans le champ Table filter (Filtre de table) ou Column filter (Filtre de colonne), respectivement. La liste affiche uniquement les tables/colonnes correspondant au texte saisi.
Cliquez sur le nom de la table pour afficher toutes ses colonnes dans le panneau de droite de la boîte de dialogue Column Selection (Sélection de colonnes).
Dans la liste à droite, cochez la case des colonnes que vous souhaitez analyser et cliquez sur OK.
Vous pouvez également déposer la règle métier directement de la vue DQ repository (Référentiel DQ) dans la table dans l'éditeur d'analyse.
Si vous cliquez-droit sur une colonne listée dans la vue Analyzed Columns (Colonnes analysées)et que vous sélectionnez Show in DQ repository view (Afficher dans la vue du référentiel DQ), la colonne sélectionnée sera automatiquement située sous la connexion correspondante dans l'arborescence.
Cliquez sur Select column B (Sélectionner la colonne B) et suivez les mêmes étapes pour sélectionner le second ensemble de colonnes, ou glissez-le dans le panneau de la colonne de droite.
Pour rapprocher les données du jeu A de celles du jeu B et non l'inverse, cochez la case Compute only number of A rows not in B (Calculer uniquement le nombre de lignes A qui ne sont pas dans B).
Cochez la case Ignore null (Ignorer les nulls) si vous souhaitez ignorer les valeurs nulles lors du rapprochement.
Si nécessaire, saisissez une clause WHERE SQL pour filtrer les données sur lesquelles exécuter l'analyse.
Finaliser et exécuter l'analyse
Big Data Platform
Cloud API Services Platform
Cloud Big Data Platform
Cloud Data Fabric
Cloud Data Management Platform
Data Fabric
Data Management Platform
Data Services Platform
Qlik Talend Cloud Enterprise Edition
Qlik Talend Cloud Premium Edition
Real-Time Big Data Platform
Pourquoi et quand exécuter cette tâche
Vous pouvez configurer des paramètres avancés, comme le nombre de connexions par analyse et son contexte.
Procédure
Dans le menu Settings (Paramètres), configurez le nombre de connexions simultanées autorisées par analyse dans le champ Number of connections per analysis (Nombre de connexions par analyse).
Vous pouvez configurer ce nombre selon les ressources disponibles de la base de données, c'est-à-dire le nombre de connexions concourantes que chaque base de données peut supporter.
Pour utiliser des contextes, cliquez sur Open context view (Ouvrir la vue de contexte).
Cliquez sur Save and Run (Enregistrer et exécuter). Un message de confirmation s'affiche.
Note InformationsConseil : Si vous souhaitez uniquement enregistrer la configuration, cliquez sur dans le coin supérieur droit.
Cliquez sur OK si vous souhaitez continuer l'opération.
Résultats
La vue Analysis results (Résultat de l’analyse) s'ouvre et affiche les résultats d'analyse.
Dans cet exemple, 0 % des données présentes dans les colonnes de la table phone1 correspondent aux mêmes données des colonnes de la table phone2. Il n'y a aucun doublon.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.

 dans le coin supérieur droit.
dans le coin supérieur droit.