
Ce que vous devez savoir à propos de certaines bases de données
Google BigQuery
Profiler des données depuis Google BigQuery nécessite une connexion JDBC.
Pour plus d'informations, consultez comment construire l'URL de connexion (uniquement en anglais) (en anglais).
Le type de données RECORD n'est pas supporté.
Lorsque vous configurez une connexion JDBC, spécifiez chaque fichier Jar extrait depuis le fichier zip.
Hive
- Allez dans la configuration du serveur Hive.
- Configurez le paramètre HiveServer2 Java Heap Size à 1 Go minimum.
Si vous choisissez de vous connectez à une base de données Hive, vous pouvez créer et exécuter différentes analyses, comme avec les autres types de bases de données.
Dans l'assistant, vous devez sélectionnez, dans la liste Distribution la plateforme hébergeant Hive. Vous devez également configurer la version et le mode de Hive.
Pour plus d'informations, consultez la documentation Apache Hadoop (uniquement en anglais) (en anglais).
Si vous décidez de modifier le nom d'utilisateur·trice en mode embarqué d'une connexion Hive, vous devez redémarrer le Studio Talend avant de pouvoir exécuter les analyses de profiling utilisant cette connexion.
- Cliquez sur le bouton à côté de Hadoop Properties et, dans la boîte de dialogue, cliquez deux fois sur le bouton [+] pour ajouter deux lignes à la table.
- Saisissez le nom des paramètres, respectivement mapred.job.map.memory.mb et mapred.job.reduce.memory.mb.
- Configurez la valeur de chaque paramètre à 1000, la valeur par défaut.
Cette valeur est appropriée pour exécuter les calculs.
| Consultez le tableau ci-dessous pour plus d'informations : | Indicateurs non supportés | Analyses non supportées |
|---|---|---|
| Avec le moteur SQL : Soundex Low Frequency Pattern (Low) Frequency Upper Quartile et Lower Quartile Median Tous les indicateurs de fréquence de date |
|
La seule analyse non supportée par Hive est Time Correlation Analysis, comme le type de données Date n'existe pas dans Hive. Pour plus d'informations sur ce type d'analyse, consultez Analyse de corrélation temporelle. |
Les options de clic-droit sur les résultats d'analyse générant des Jobs pour valider, standardiser ou dédoublonner des données ne sont pas supportés pour Hive. Pour plus d'informations sur ces Jobs, consultez Validation des données.
Hive et HBase
Lorsque vous choisissez de vous connecter à une base de données Hive ou HBase pour créer et exécuter des analyses différentes, dans l'assistant de connexion, vous devez, comme expliqué ci-dessus, sélectionner dans la liste Distribution la plateforme hébergeant Hive ou HBase.
- Le paramètre est yarn.application.classpath
- La valeur est /etc/hadoop/conf,/usr/lib/hadoop/,/usr/lib/hadoop/lib/,/usr/lib/hadoop-hdfs/,/usr/lib/hadoop-hdfs/lib/,/usr/lib/hadoop-yarn/,/usr/lib/hadoop-yarn/lib/,/usr/lib/hadoop-mapreduce/,/usr/lib/hadoop-mapreduce/lib/
Microsoft SQL Server
Microsoft SQL Server 2012 et les versions supérieures sont supportées.
Si vous choisissez de vous connecter à la base de donnée Microsoft SQL Server via l'authentification Windows , vous pouvez sélectionnez Microsoft ou JTDS open source dans la liste Db Version.
Lorsque vous utilisez une base de données Microsoft SQL Server pour stocker les résultats des rapports, les pilotes Microsoft JDBC et JTDS open source sont supportés.
Si vous créez une connexion à une base de données Azure SQL afin de stocker les rapports et les résultats d'analyse, saisissez ssl=require dans le champ Additional parameters des paramètres de connexion à la base de données.
- Téléchargez la version 1.3.1 du pilote JTDS depuis le site Web JTDS (uniquement en anglais) (en anglais).
- Extrayez les fichiers de l'archive et copiez le fichier ntlmauth.dll présent dans x64/SSO ou x86/SSO, selon votre système d'exploitation.
- Collez le fichier ntlmauth.dll dans le dossier %SYSTEMROOT%/system32
Si vous rencontrez l'erreur suivante : Échec de l'authentification unique : Bibliothèque SSPI native non chargée, copiez le fichier ntlmauth.dll dans le dossier bin du JRE utilisé par le Studio Talend.
L'interclassement utilisé par la base de données de Microsoft SQL Server doit être sensible à la casse, sinon la génération du rapport pourrait échouer. Vous pourriez rencontrer des erreurs telles que java.sql.SQLException: Invalid column name 'rep_runtime'. Pour plus d'informations concernant les règles d'interclassement, consultez Nom de classement Windows (uniquement en anglais).
Le type de données ntext n'est pas supporté.
MySQL
Lorsque vous créez une connexion à MySQL via JDBC, il n'est pas obligatoire d'inclure le nom de la base de données à l'URL JDBC. Que l'URL de connexion à la base de données spécifiée dans le champ JDBC URL contienne le nom de la base de données ou non, tous les catalogues sont récupérés.
Par exemple, si vous indiquez jdbc:mysql://192.168.33.41:3306/tbi?noDatetimeStringSync=true où tbi est le nom de la base de données, ou bien jdbc:mysql://192.168.33.41:3306/?noDatetimeStringSync=true, tous les catalogues sont récupérés.
Afin de supporter les paires de substitution, vous devez modifier les propriétés suivantes dans le fichier de configuration du serveur MySQL :
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
character-set-server=utf8mb4Netezza
La base de données Netezza ne supporte pas les expressions régulières. Si vous souhaitez utiliser les expressions régulières avec cette base de données, vous devez :
- Installer le package SQL Extensions Toolkit dans un système Netezza. Utilisez la fonction regex_like fournie dans ce toolkit dans le modèle SQL comme documenté dans IBM Netezza SQL Extensions toolkit installation and setup (uniquement en anglais) (en anglais).
- Ajoutez la définition de l'indicateur pour Netezza dans le dossier Pattern Matching du Studio Talend sous .
Le modèle de requête à définir pour Netezza se présente comme suit : SELECT COUNT(CASE WHEN REGEXP_LIKE(<%=COLUMN_NAMES%>,<%=PATTERN_EXPR%>) THEN 1 END), COUNT FROM <%=TABLE_NAME%><%=WHERE_CLAUSE%>.
Oracle
Afin de supporter les paires de substitution, le paramètre NLS_CHARACTERSET de la base de données doit être configuré à UTF-8 ou AL32UTF8.
Les paramètres NLS_CHARACTERSET par défaut sont :
- NLS_CHARACTERSET=WE8ISO8859P15
- NLS_NCHAR_CHARACTERSET=AL16UTF16
Oracle Custom (personnalisé)
Pour vous connecter à une base de données Oracle utilisant le type de base de données Oracle Custom (personnalisé) dans la liste DB Type, cochez les cases Use SSL Encryption (Utiliser le chiffrement SSL) et Need Client Authentication (Nécessite l'authentification du client) et renseignez les champs Trust Store Path (Chemin du TrustStore) et Trust Store Password (Mot de passe du TrustStore).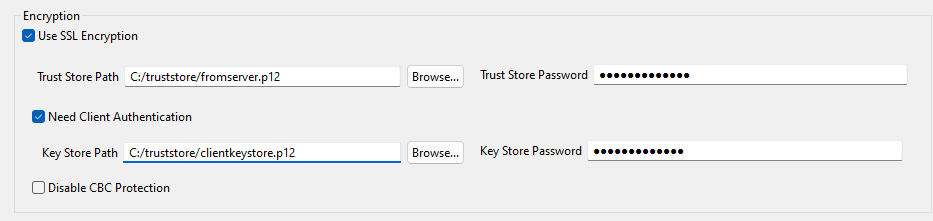
PostgreSQL
Lorsque vous vous connectez à une base de données PostgreSQL via une connexion JDBC, les types de données INT4 et INT8 sont remplacés par un type de données String. Par conséquent, si votre analyse utilise l'algorithme T-Swoosh, les fonctions de consolidation sont pour les chaînes de caractères et non pour les nombres.
- Fermez l'analyse et passez à la perspective Integration.
- Développez le nœud Metadata et cliquez-droit sur la connexion à la base de données .
- Cochez la case de la table à mettre à jour.
- Lorsque Creation status est configuré à Success, cliquez sur Next.
- Si les colonnes sans type de base de données doivent être de type Integer, configurez DB Type à INT.
- Cliquez sur Finish et fermez la boîte de dialogue.
- Passez à la perspective Profiling et ouvrez l'analyse.
- Dans Survivorship Rules for Columns, supprimez et ajoutez à nouveau les colonnes mises à jour. Vous pouvez voir les fonctions de consolidation pour les nombres (Largest et Smallest).
SAP HANA
Profiler des données depuis SAP HANA est possible uniquement pour les schémas Table, View et Calculation View.
Les indicateurs statistiques de fréquence Soundex ne supportent que l'alphabet anglais.
Snowflake
Profiler des données depuis Snowflake nécessite une connexion JDBC.
Lorsque le nom et la structure de la table sont identiques, vous pouvez passer d'un contexte à l'autre pour passer d'une base de données à l'autre ou d'un schéma à l'autre. L'URL JDBC permet de passer d'un catalogue à l'autre ou d'un schéma à l'autre. Après avoir changé de contexte, seul le catalogue ou le schéma de l'URL est affiché sous le nœud de connexion.
Pour plus d'informations, consultez Configuring the JDBC Driver (uniquement en anglais) (en anglais).
Vous ne pouvez utiliser de connexion créée dans le nœud Snowflake dans la perspective Integration.
Teradata
Si vous choisissez de vous connecter à la base de données Teradata, sélectionnez Yes pour l'option USE SQL Mode, afin de permettre au Studio Talend d'utiliser les requêtes SQL pour récupérer les métadonnées. Le pilote JDBC n'est pas recommandé avec cette base de données en raison d'éventuelles mauvaises performances.
Dans la base de données Teradata, la fonction d'expressions régulières est installée par défaut à partir de la version 14. Si vous souhaitez utiliser les expressions régulières avec une version plus ancienne de la base de données, vous devez installer une fonction personnalisée dans Teradata et ajouter la définition de l'indicateur pour Teradata dans le Studio Talend.