Comparaison de colonnes identiques dans différentes tables
Avant de commencer
Au moins une connexion à une base de données doit avoir été définie dans la perspective Profiling. Pour plus d'informations, consultez Se connecter à une base de données.
Dans cette vue, vous pouvez également accéder aux données actualisées via la perspective Data Explorer.
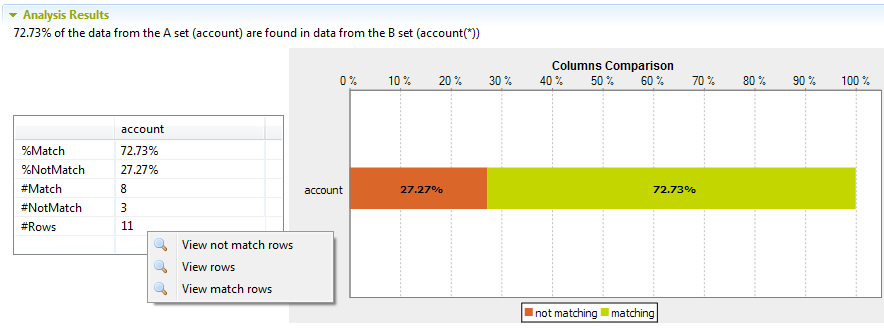
- View match rows : pour accéder à une liste de toutes les lignes pouvant correspondre aux deux ensembles de colonnes identiques.
- View not match rows : pour accéder à une liste de toutes les lignes ne pouvant pas correspondre aux deux ensembles de colonnes identiques.
- View rows : pour accéder à une liste de toutes les lignes dans les deux ensembles de colonnes identiques.
La capture d'écran ci-dessous montre la liste de toutes les lignes pouvant correspondre dans les deux ensembles, huit dans cet exemple.
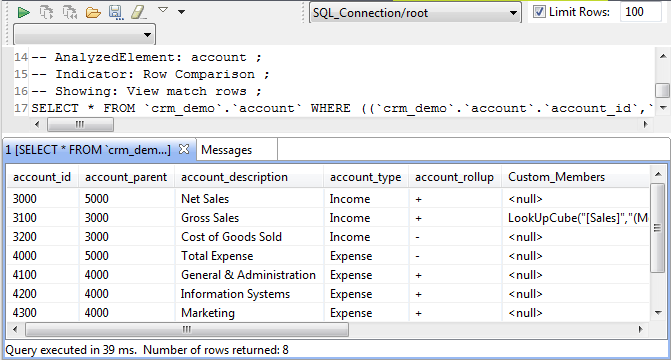
Dans l'éditeur SQL, vous pouvez sauvegarder la requête exécutée et la lister sous les dossiers Libraries > Source Files dans la vue DQ Repository, si vous cliquez sur l'icône de sauvegarde dans la barre d'outils de l'éditeur. Pour plus d'informations, consultez Sauvegarder les requêtes exécutées sur les indicateurs.
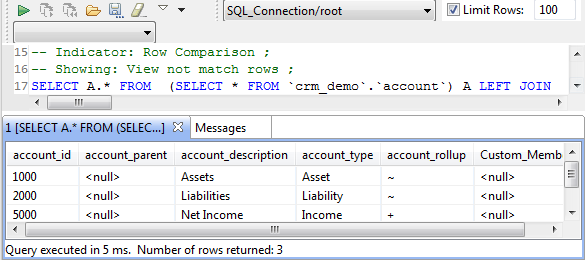
La capture d'écran ci-dessous illustre la liste de toutes les lignes ne pouvant correspondre dans les deux ensembles, trois dans cet exemple.
Définir l'analyse de redondance
Procédure
-
Cliquez-droit sur le dossier Analyses et sélectionnez New Analysis.
 L'assistant Create New Analysis s'ouvre.
L'assistant Create New Analysis s'ouvre.
Sélectionner les colonnes à comparer
Procédure
-
Développez le nœud DB connections, parcourez l'arborescence jusqu'à la base de données souhaitée, sélectionnez les colonnes que vous voulez analyser puis cliquez sur Finish pour fermer l'assistant.
Un fichier pour l'analyse nouvellement créée apparaît sous le nœud Analysis dans la vue DQ Repository. L'éditeur d'analyse s'ouvre avec les métadonnées définies de l'analyse.
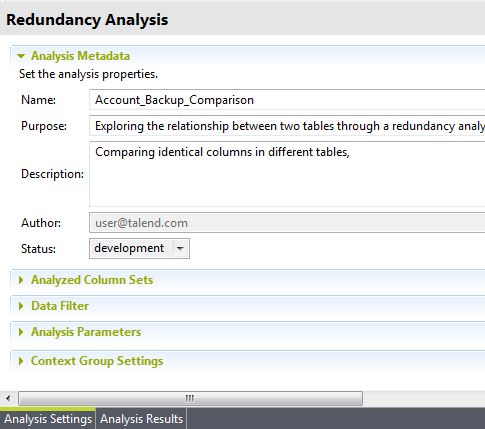 L'affichage de l'éditeur d'analyse dépend des paramètres que vous avez configurés dans la fenêtre des Preferences (Préférences). Pour plus d'informations, consultez Configurer les préférences des éditeurs et des résultats d'analyse.
L'affichage de l'éditeur d'analyse dépend des paramètres que vous avez configurés dans la fenêtre des Preferences (Préférences). Pour plus d'informations, consultez Configurer les préférences des éditeurs et des résultats d'analyse. -
Cliquez sur Analyzed Column Sets pour afficher la vue où analyser deux ensembles de colonnes identiques.
Dans cet exemple, l'objectif est de comparer des colonnes identiques dans les tables account et account_back.
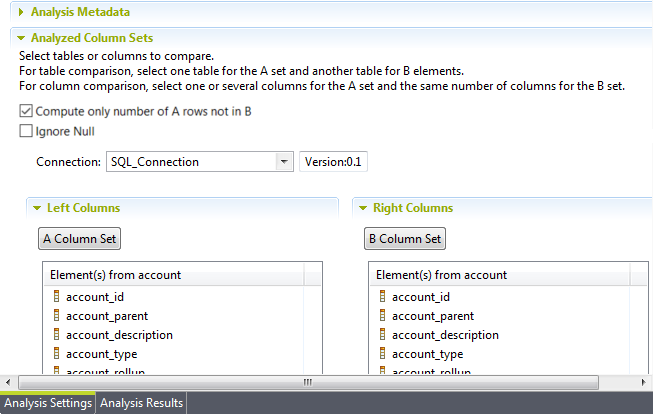
-
Dans la liste à droite, cochez la case des colonnes que vous souhaitez analyser et cliquez sur OK.
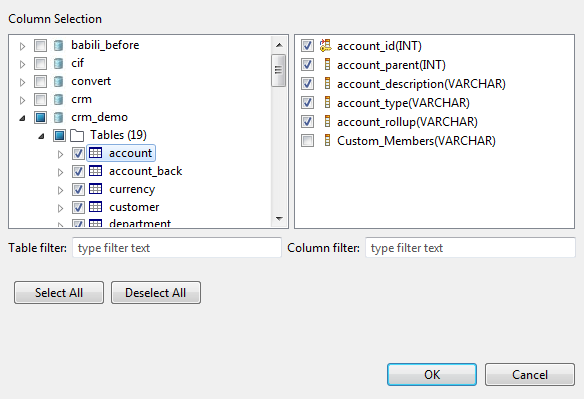 Vous pouvez glisser les colonnes à analyser directement de la vue DQ Repository dans l'éditeur.Si vous cliquez-droit sur une colonne listée dans la vue Analyzed Columns et que vous sélectionnez Show in DQ Repository view, la colonne sélectionnée sera automatiquement située sous la connexion correspondante dans l'arborescence.
Vous pouvez glisser les colonnes à analyser directement de la vue DQ Repository dans l'éditeur.Si vous cliquez-droit sur une colonne listée dans la vue Analyzed Columns et que vous sélectionnez Show in DQ Repository view, la colonne sélectionnée sera automatiquement située sous la connexion correspondante dans l'arborescence.
Finaliser et exécuter l'analyse
Procédure
Résultats
Dans cet exemple, 72.73 % des données présentes dans les colonnes de la table account peuvent être rapprochées des mêmes données de la colonne de la table account_back.