
Écrire la sortie dans Azure ADLS Gen1
Deux composants de sortie sont configurés pour écrire les données relatives aux films attendues et les données relatives aux films rejetées dans différents répertoires dans un dossier Azure ADLS Gen1.
Avant de commencer
- Assurez-vous que votre cluster Spark dans Databricks a bien été créé et est en cours de fonctionnement. Pour plus d'informations, consultez Créer un espace de travail Azure Databricks dans la documentation Azure.
- Assurez-vous d'avoir ajouté les propriétés Spark concernant les identifiants à utiliser pour accéder à votre système Azure Data Lake Storage Gen1, une par ligne.
spark.hadoop.dfs.adls.oauth2.access.token.provider.type ClientCredential spark.hadoop.dfs.adls.oauth2.client.id <your_app_id> spark.hadoop.dfs.adls.oauth2.credential <your_authentication_key> spark.hadoop.dfs.adls.oauth2.refresh.url https://login.microsoftonline.com/<your_app_TENANT-ID>/oauth2/token - Vous devez avoir un compte Azure.
- Le service Azure Data Lake Storage à utiliser doit avoir été créé. Votre application Azure Active Directory doit avoir les droits d'accès appropriés à ce service. Vous pouvez demander à l'administrateur·trice de votre système Azure ou suivre la procédure décrite dans Moving data from ADLS Gen1 to ADLS Gen2 using Azure Databricks (en anglais).
Procédure
-
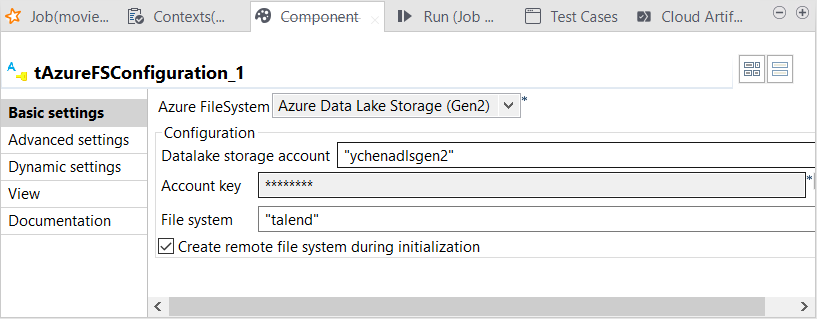
Double-cliquez sur le composant tAzureFSConfiguration pour ouvrir sa vue Component.
Exemple
-
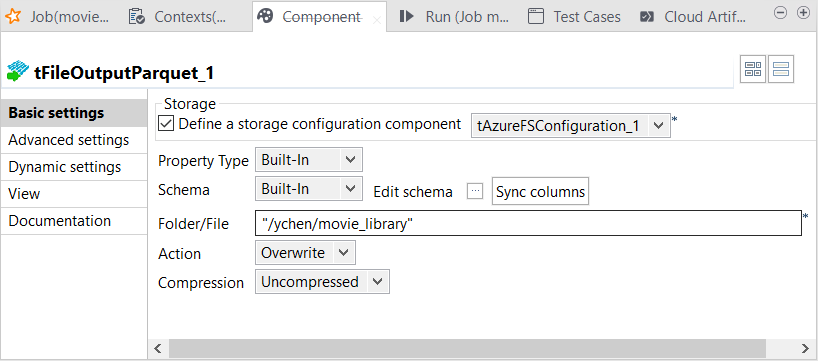
Double-cliquez sur le tFileOutputParquet recevant le lien out1.
Sa vue Basic settings est ouverte dans la partie inférieure du Studio Talend.
-
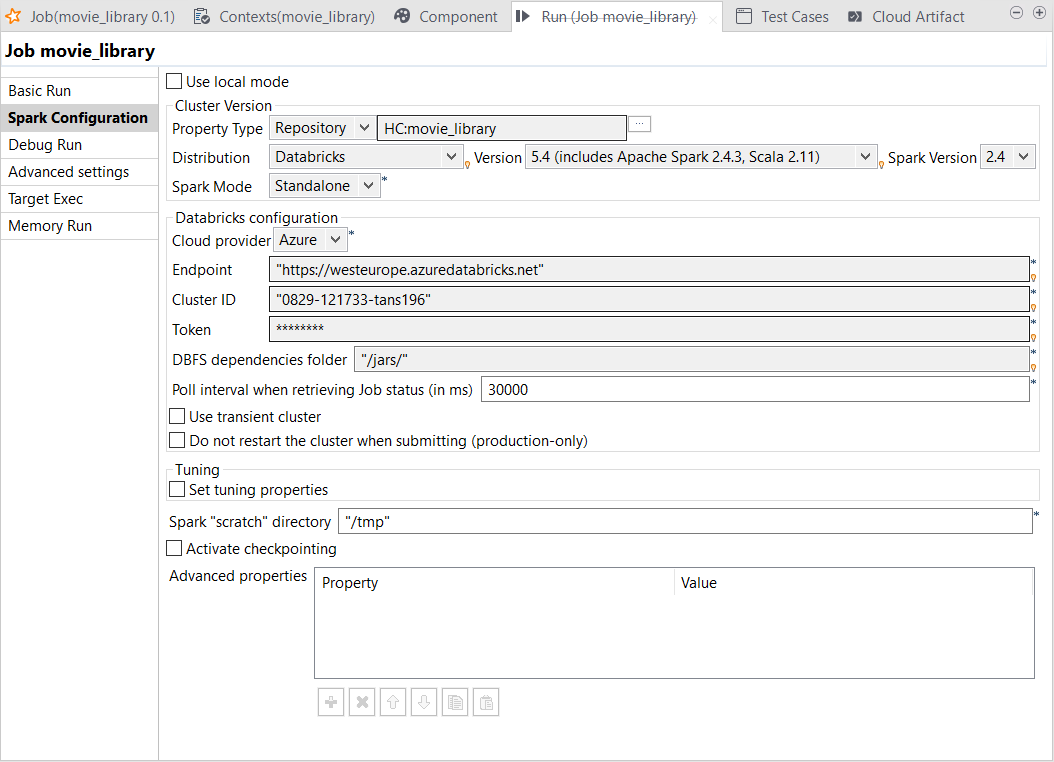
Dans la vue Run, cliquez sur l'onglet Spark Configuration.
Résultats
La vue Run s'ouvre automatiquement dans la partie inférieure du Studio Talend.
Cela fait, vous pouvez vérifier, par exemple dans Microsoft Azure Storage Explorer, que la sortie a été écrite dans le dossier ADLS Gen1.