
Configurer la connexion à votre plateforme Big Data
Configurer la connexion à une distribution Hadoop donnée dans le Repository vous permet d'éviter de configurer cette connexion à chaque fois que vous devez utiliser la même plateforme.
La plateforme Big Data à utiliser dans cet exemple est un cluster Databricks V5.4, avec Azure Data Lake Storage Gen2.
Avant de commencer
-
Assurez-vous que votre cluster Spark dans Databricks a bien été créé.
Pour plus d'informations, consultez Créer un espace de travail Azure Databricks (uniquement en anglais) dans la documentation Azure.
- Vous devez avoir un compte Azure.
- Le compte de stockage Azure Data Lake Storage Gen2 à utiliser doit avoir été créé et vous devez avoir les droits en lecture écriture sur celui-ci. Pour plus d'informations concernant la création de ce type de compte de stockage, consultez Créer un compte de stockage Azure Data Lake Storage Gen2 (uniquement en anglais) dans la documentation Azure.
Pourquoi et quand exécuter cette tâche
Procédure
-
Dans l'onglet Configuration de la page de votre cluster Databricks, faites défiler jusqu'à l'onglet Spark au bas de la page.
Exemple
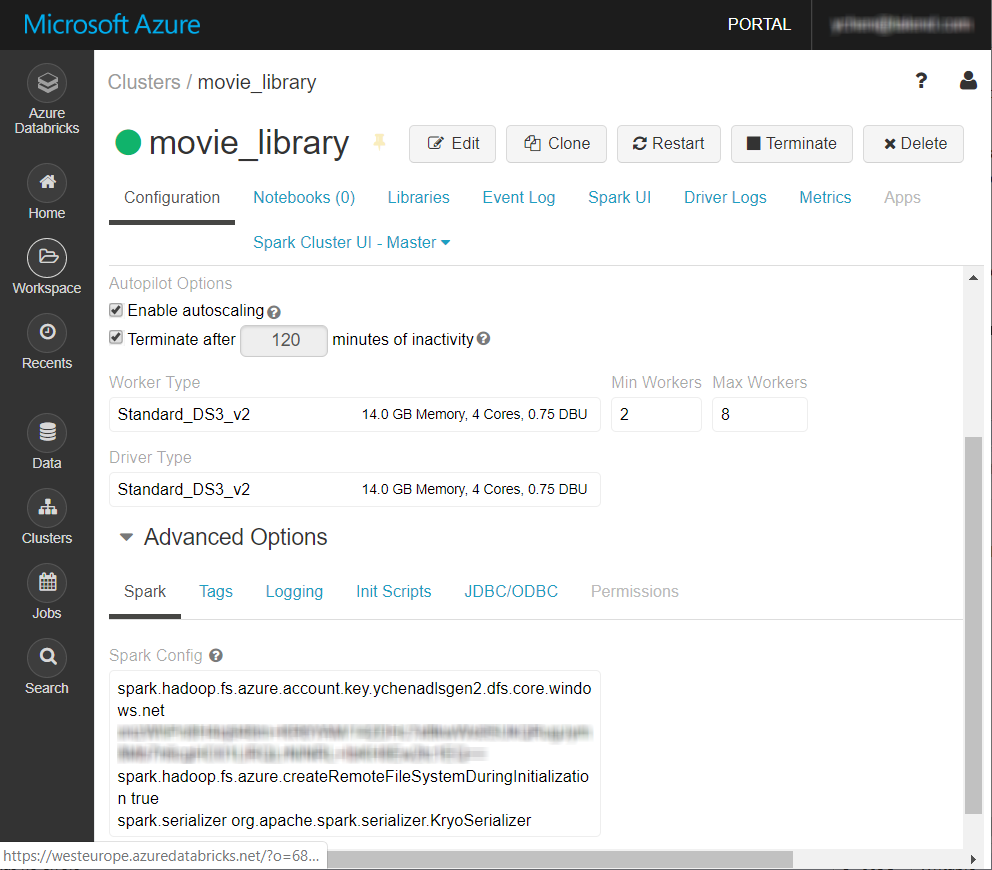
-
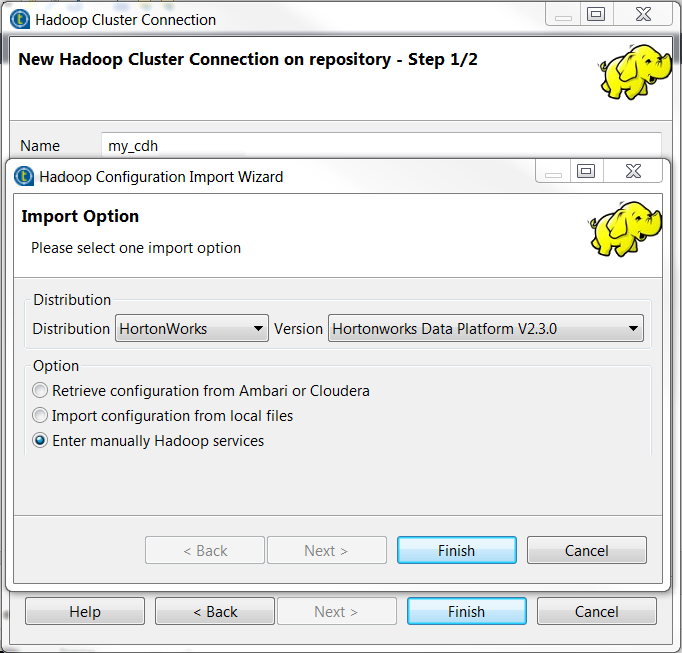
Cochez la case Enter manually Hadoop services afin de saisir manuellement les informations de configuration pour la connexion Databricks en cours de création.
Résultats
La nouvelle connexion, nommée movie_library dans cet exemple, est affichée dans le dossier Hadoop cluster de la vue Repository.