
Normaliser des enregistrements complexes
Avant de commencer
-
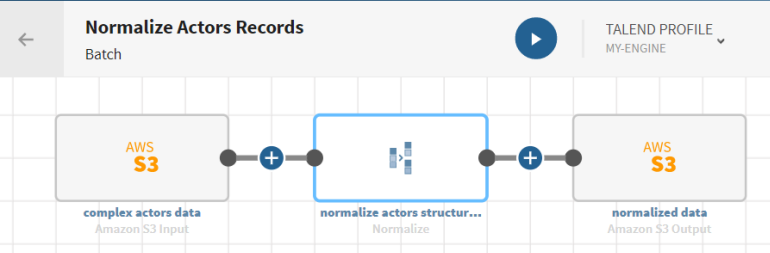
Vous avez précédemment créé une connexion au système stockant vos données source.
Ici, une connexion Amazon S3.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Ici, des données hiérarchiques concernant des acteurs et contenant leur ID, nom, pays, etc.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un fichier stocké sur Amazon S3.
Procédure
-
Cliquez sur le bouton
 et ajoutez un processeur Normalize au pipeline. Le panneau de Configuration s’affiche.
et ajoutez un processeur Normalize au pipeline. Le panneau de Configuration s’affiche.
-
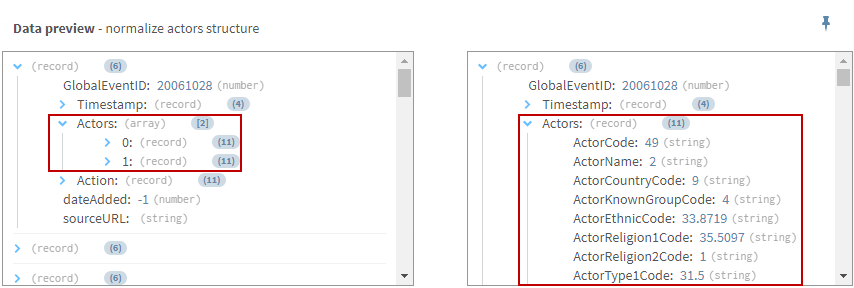
(Facultatif) Examinez la prévisualisation du processeur Normalize afin de comparer vos données avant et après l'opération de normalisation.
Résultats
Votre pipeline est en cours d’exécution, les enregistrements sont normalisés et la sortie est envoyée au système cible défini.