
Agréger des informations clients pour calculer les achats
Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Téléchargez et extrayez le fichier aggregate-customers.zip. Il contient une liste hiérarchique des données client·es, notamment l'ID ou les informations produits comme les titres et les prix des livres.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un fichier stocké dans HDFS.
Procédure
-
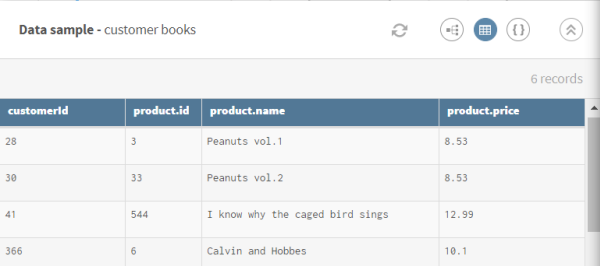
Cliquez sur ADD SOURCE pour ouvrir le panneau vous permettant de sélectionner vos données source, ici une liste de données clients hiérarchiques concernant des achats de livres.
Exemple
-
Cliquez sur le bouton
 et ajoutez un processeur Aggregate au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Aggregate au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
Vous pouvez prévisualiser les données calculées après l'opération d'agrégation : les livres achetés et la somme dépensée par client.
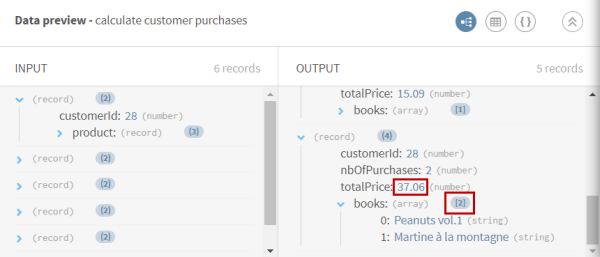
Résultats
Votre pipeline est en cours d'exécution, les achats de livres sont agrégés par client et le flux de sortie est envoyé dans les systèmes cible définis.