
Définir la campagne Grouping
La campagne que vous créez permet aux data stewards de libeller un échantillon d'enregistrements suspects dans le contexte d'un rapprochement de grands volumes de données, à l'aide de l'apprentissage automatique dans Spark.
Procédure
-
Sélectionnez Grouping (Regroupement) comme type de campagne.
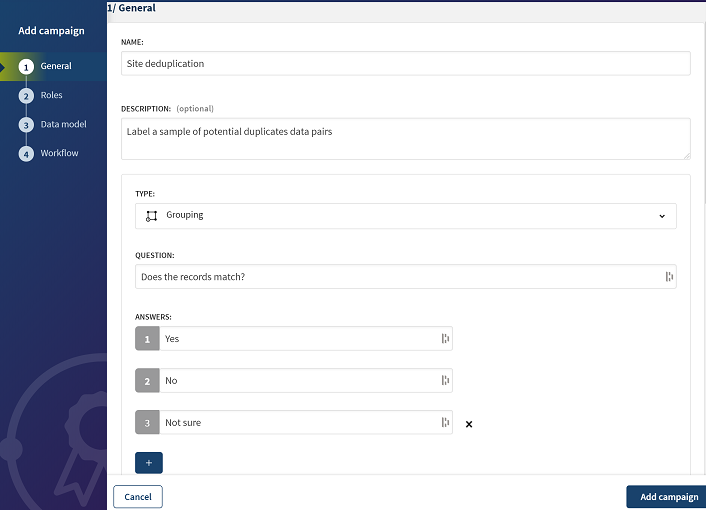
-
Utilisez le
 pour ajouter un choix supplémentaire et saisissez les réponses dans les champs Answers (Réponses), comme dans la capture d'écran ci-dessus.
pour ajouter un choix supplémentaire et saisissez les réponses dans les champs Answers (Réponses), comme dans la capture d'écran ci-dessus.