
Configurer un modèle de données dans la campagne Merging
Les modèle de données utilisés dans une campagne décident de la structure des données à gérer. Ils sont utilisés pour la validation syntaxique et sémantique des données.
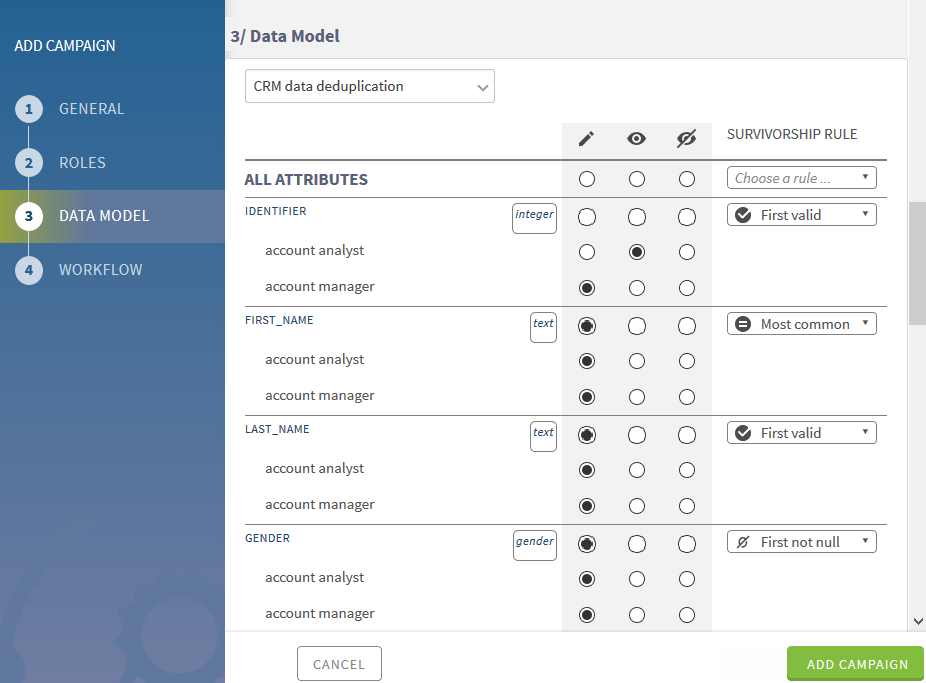
Vous pouvez définir les droits d'accès en lecture/écriture par rôle pour chacun des attributs listés dans un modèle de données.
Procédure
-
Dans la page ADD CAMPAIGN, cliquez sur DATA MODEL et sélectionnez dans la liste de modèles la structure des données à utiliser dans la campagne CRM data deduplication.
La liste Data Model donne accès à tous les modèles de données définis.
-
Sélectionnez un bouton à côté de chaque attribut dans la structure de données afin de configurer les permissions par attribut et par data steward, ainsi que pour définir qui peut voir/modifier quels attributs.
Option Description 
Donne un accès en lecture/écriture à l'attribut dans le modèle de données. 
Donne un accès en lecture seule à l'attribut dans le modèle de données. Ce type d'accès est utile si le·a data steward doit accéder aux informations pour prendre une décision mais ne doit pas modifier la valeur, par exemple des identifiants uniques des autres éléments liés à l'entité que le·a data steward consulte, ou des données que vous savez être fiables et qui ne doivent pas être modifiées.
Ne donne aucun accès à l'attribut. Masquer un attribut est utile si les informations sont sensibles et ne doivent pas être visibles par le·a data steward, par exemple pour des informations financières. Un autre exemple d'attribut à masquer si les informations ne sont pas utiles à la·au data steward est l'identifiant technique, même s'il doit être propagé en tant que partie de la tâche.
Exemple
Dans la campagne CRM Data Deduplication, vous donnez un accès en lecture seule à l'attribut d'identifiant aux data stewards ayant le rôle account analyst.