
Configuring the components
Procedure
-
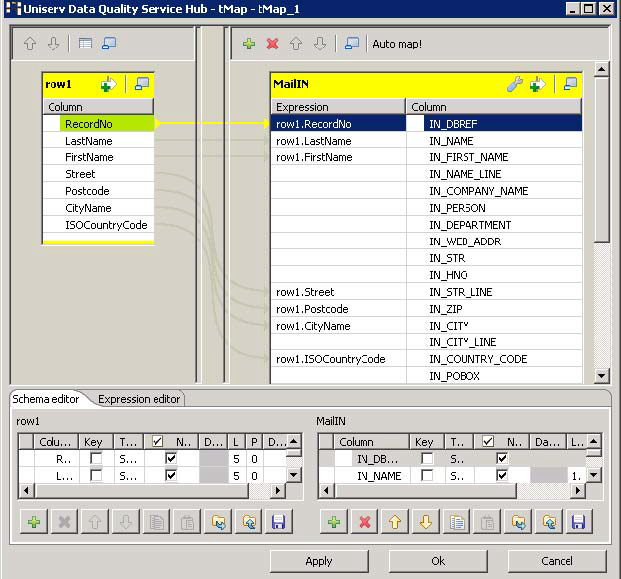
Double-click tMap_1 to open the schema
mapping window. On the left is the structure of the input file and on the right
is the schema of tUniservRTMailSearch. At the
bottom lies the Schema Editor, where you can
find the attributes of the individual columns and edit them.
-
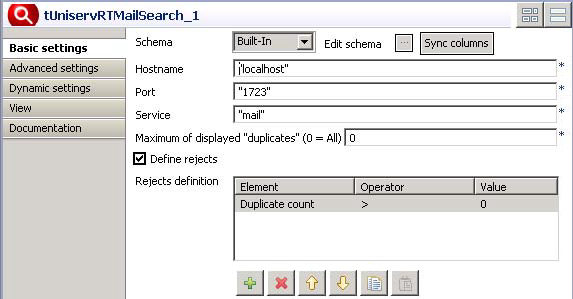
Double-click tUniservRTMailSearch to open its
Basic settings view.
-
The only field that must be assigned manually is the reference ID. In order to
do so, drag OUT-DBREF from the left side onto
the field IN_DBREF on the right side.
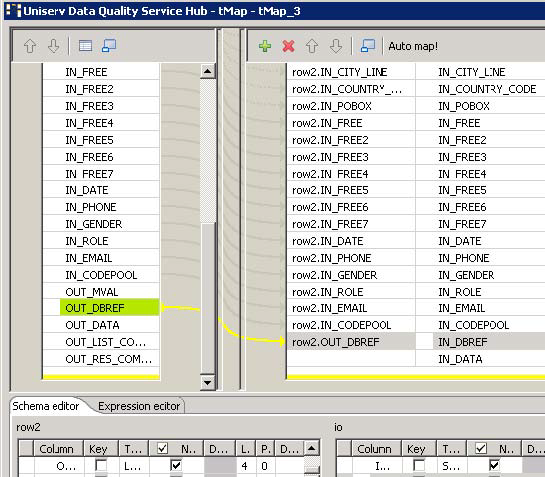 Click OK to close the dialog box.
Click OK to close the dialog box. -
Double-click tUniservRTMailOutput to open the
Basic settings view.
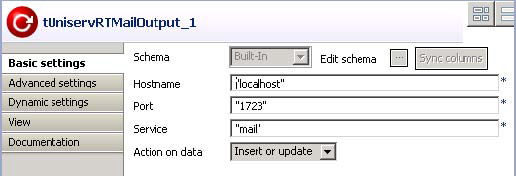 From the Action on Data list, select Insert or update. This way, all new contacts are added to the index pool.
From the Action on Data list, select Insert or update. This way, all new contacts are added to the index pool.