Configuring data import
Procedure
-
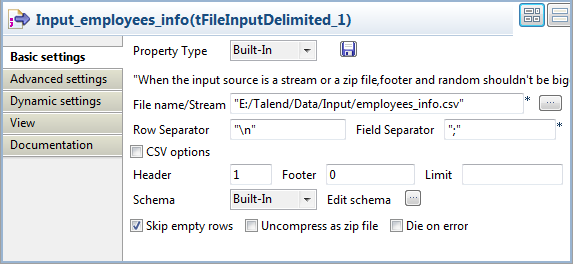
Double-click the tFileInputDelimited
component to open its Basic settings view
on the Component tab.
-
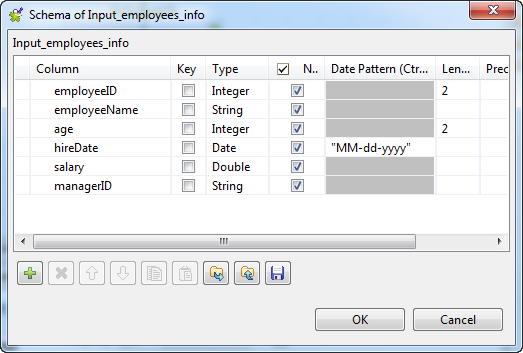
Click the [...] button next to Edit schema to open the Schema dialog box, and define the input schema based on
the structure of the input file. In this example, the input schema is
composed of six columns: employeeID
(integer), employeeName (String),
age (Integer), hireDate (Date), salary (Double), and managerID (String).
When done, click OK to close the Schema dialog box and propagate the schema to the next component.
-
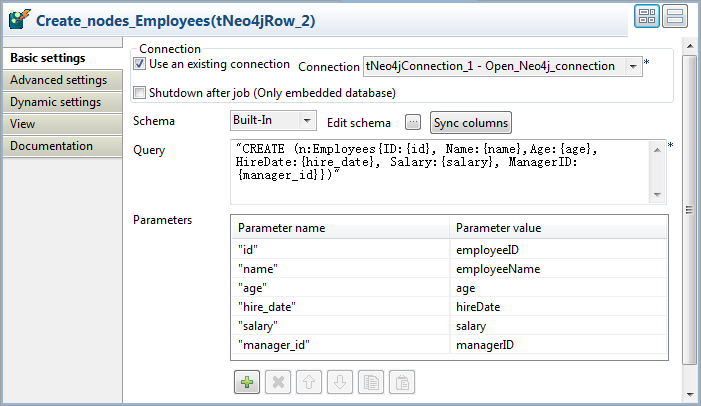
Double-click the tNeo4jRow component to
open its Basic settings view on the
Component tab.
-
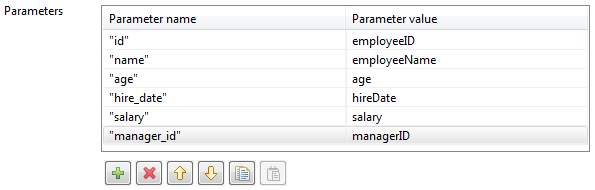
In the Parameters table, type in the
variable parameters in the Parameter field
in accordance with your Cypher query , and map each of them with an input
schema column by selecting it from the Parameter
value list field.