| オプション |
操作 |
| [New Connection] (新規接続) |
ウィザードを開き、エディター内からデータソースへの接続を作成します。 このセクションの上部にある[Connection] (接続)フィールドには、Talend Studioで作成した接続がすべてリスト表示されています。
|
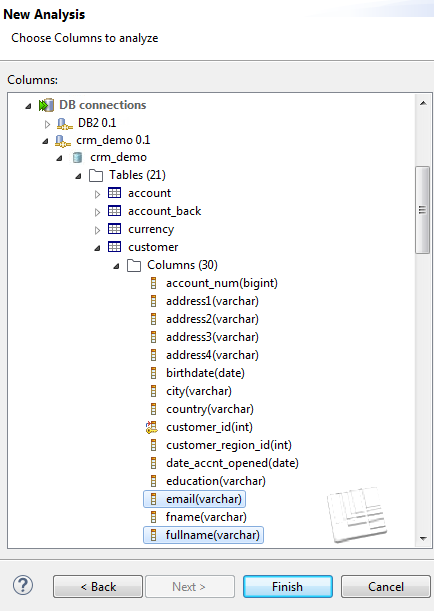
| [Select Columns] (カラムを選択) |
[Column Selection] (カラム選択)ダイアログボックスを開くと、テーブル内にリスト表示されているカラムを選択し、その選択を分析または変更できます。開いたダイアログボックスで[Table filter] (テーブルフィルター)フィールドや[Column filter] (カラムフィルター)フィールドに必要なテキストを入力すると、テーブルやカラムのリストをフィルタリングできます。 |
| [Select Indicators] (インジケーターを選択) |
[Indicator Selection] (インジケーターの選択)ダイアログボックスを開き、カラムのプロファイリングに使用するインジケーターをここで選択できます。 |
| [n first rows] (最初のn行)または[n random rows] (ランダムなn行) |
選択したカラムから最初のNデータレコードをテーブルにリスト、または選択したカラムからランダムなNレコードをリスト表示します。 |
| [Refresh Data] (データを更新) |
設定した条件に従って、選択したカラムにデータを表示します。 |
| [Run with sample data] (サンプルデータで実行) |
[Limit] (制限)フィールドでサンプルデータセットにのみ分析を実行します。 |

 情報メモ注: DB2データベースでプロファイリングをする場合、テーブルのカラム名に二重引用符が使用されていても、カラムを取得する際に二重引用符は取得されません。そのため、DB2データベースのテーブルではカラム名に二重引用符を使用しないことが推奨されます。
情報メモ注: DB2データベースでプロファイリングをする場合、テーブルのカラム名に二重引用符が使用されていても、カラムを取得する際に二重引用符は取得されません。そのため、DB2データベースのテーブルではカラム名に二重引用符を使用しないことが推奨されます。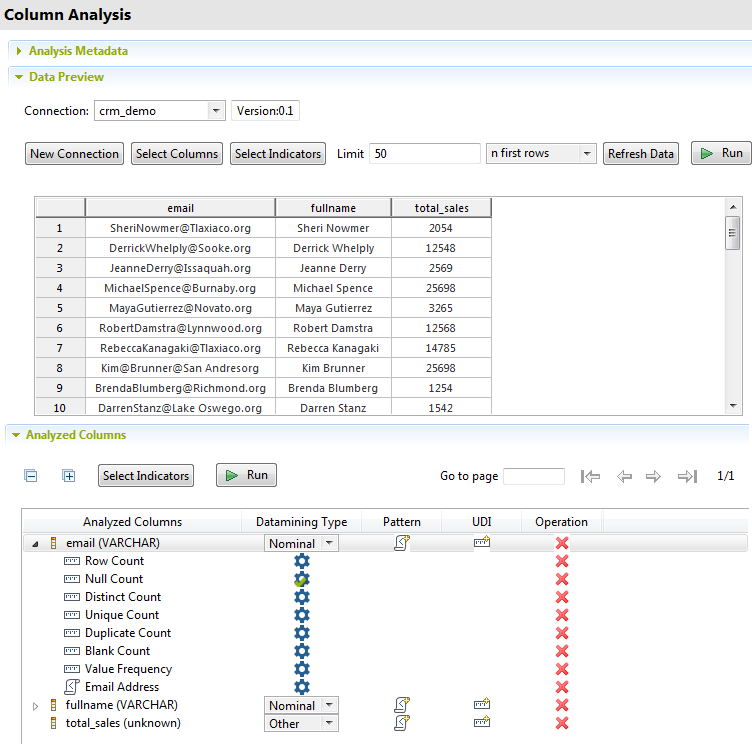 この例では、フルネーム、メールアドレス、売上額を分析します。
この例では、フルネーム、メールアドレス、売上額を分析します。